

데이터 2/3차 정규화 [응용]
체계적인 데이터 관리를 위한 지침서! - 2/3차 정규화
이 강의에서는 엑셀에서 자주 마주치는 종속 데이터 관리 문제를 2차·3차 정규화로 해결하는 방법을 다룹니다. 데이터를 거래처·제품·담당자 단위로 독립적인 테이블로 분리해 변경과 삭제 시 발생하는 오류를 줄이고, 엑셀의 표 기능과 LOOKUP 함수를 함께 사용해 분리된 데이터를 안정적으로 연결하는 흐름까지 단계별로 정리합니다.
![데이터 2/3차 정규화 [응용]](https://i.ytimg.com/vi/eWQEgYx4b6E/maxresdefault.jpg)
실습자료를 준비했어요
수업에서 사용한 예제 파일과 보충 자료를 한 곳에 정리했습니다!👇
![데이터 1차 정규화 [기초]](https://www.oppadu.com/wp-content/uploads/2018/02/1-4-Thumbnail-New-300x169.png)





실습 가이드
이번 강의에서는 데이터 2차/3차 정규화의 개념과 엑셀 적용 방법을 살펴봅니다. 1차 정규화를 먼저 학습하고 싶다면 이전 강의를 먼저 참고하세요!
2차 정규화 이상의 작업은 데이터베이스(DB)단에서 처리하는 것이 일반적입니다. 따라서 데이터 2차/3차 정규화는 ERP나 POS와 같은 전용 시스템에서 주로 이루어집니다. (엑셀은 1차 정규화만 적용해도 대부분의 업무에서 충분합니다.)
다만 상황에 따라 엑셀 안에서 많은 데이터를 직접 관리해야 할 때가 있습니다. 이 경우 1차 정규화만으로는 체계적인 관리가 어려운데요. 이번 강의에서는 그러한 상황을 대비하여 2차/3차 정규화의 기본 개념을 정리하고, 엑셀에서 어떻게 적용하는지 실전 예제로 함께 살펴봅니다.
또한 엑셀의 표 기능과 함께 활용하면 매우 유용한 LOOKUP 함수 사용법도 같이 다룹니다.
다시 강조하자면, 엑셀은 테이블 간 관계 형성을 기반으로 한 데이터 관리에는 적합하지 않은 도구입니다. (파워피벗·파워쿼리를 사용해도 속도와 효율 측면에서 전용 데이터베이스에 비해 한계가 있습니다.) 따라서 테이블 간 관계가 3단계 이상으로 이어지는 데이터 구조라면, SQL 또는 Access처럼 관계형 데이터 관리에 특화된 프로그램을 사용하는 것을 권장합니다.
1] '정규화'를 너무 어렵게 생각하지 마세요
1-A. 정규화는 글로 익히기보다 직접 다뤄보면서 이해하는 것이 가장 빠릅니다.
이번 강의에서는 2단계, 3단계 정규화를 함께 살펴봅니다. 2차/3차 정규화는 엑셀을 효율적으로 다루고자 한다면 '가급적' 익혀두는 것이 좋습니다.
다만 별도의 ERP 프로그램을 사용하고, 해당 시스템에서 원본 데이터(Raw Data)를 받아 엑셀로 후처리하는 환경이라면, 1차 정규화(중복 데이터 제거) 수준만 이해해도 엑셀 작업에는 큰 무리가 없습니다.
1-B. 다만 엑셀 자체도 점차 진화하고 있습니다.
엑셀은 이제 단순한 '스프레드시트'를 넘어 데이터베이스 도구로도 활용할 수 있도록 발전하고 있습니다. 파워쿼리 및 파워피벗의 기능은 앞으로도 꾸준히 강화될 것입니다.(반면, MS Access(엑세스) 프로그램은 2013 버전 이후로 사실상 업데이트가 중단되었습니다.)
오피스 365와 엑셀 2019부터 추가된 동적배열 함수를 비롯해, 사용자 편의 기능도 꾸준히 개선되고 있습니다. 이제 엑셀을 잘 다룬다는 것은 복잡한 수식·공식을 잘 쓰는 능력이라기보다는, 데이터를 체계적으로 관리하고 처리하는 능력에 가깝습니다. 즉, 데이터 구조만 잘 갖춰져 있다면 엑셀의 기본 함수와 기능만으로도 다양한 분석을 충분히 수행할 수 있습니다.
2] 2,3차 정규화가 필요한 이유
2-A. 1차 정규화 이후에도 남아있는 문제점
아래 표를 보면 물품명과 물품분류는 서로 '종속 관계'에 있습니다. 즉, 물품명이 바뀌면 물품분류도 해당 물품에 맞춰 함께 갱신되어야 합니다. 따라서 데이터 관점에서 하나의 변경 사항이 발생할 때마다 두 번의 작업이 이루어지며, 종속된 데이터 항목이 많아질수록 변경 작업량은 기하급수적으로 늘어납니다.
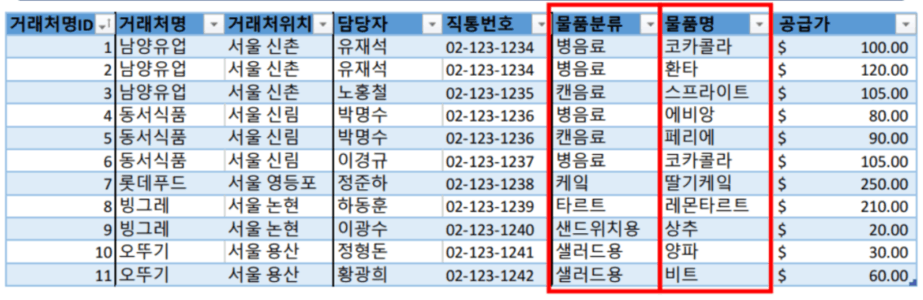
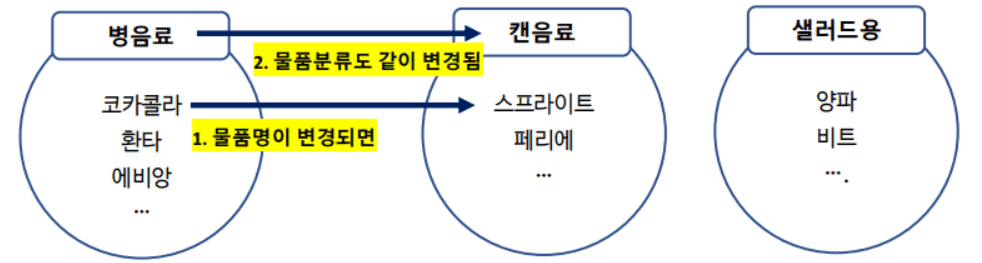
2-B. 종속된 데이터를 다룰 때 엑셀에서 발생하는 문제
엑셀에서는 종속된 데이터를 처리하기 위해 VLOOKUP 함수, LOOKUP 함수, INDEX/MATCH 함수 등을 사용합니다. 다만 이렇게 함수에 의존할 경우 다음 3가지 한계가 있습니다.
- 파일 크기가 비약적으로 커집니다.
- 참조하는 값이 변경되면 #N/A 오류가 발생할 수 있습니다.
- 파일 크기가 커지면 데이터 처리 속도가 함께 느려집니다.
따라서 데이터 양이 많은 환경이라면 효율적인 데이터 관리를 위해 아래 2차/3차 정규화를 적용하는 것을 검토할 수 있습니다.
3] 데이터 2/3차 정규화 적용해보기
3-A. 2차 정규화를 적용한 거래처별 제품 목록표
2차 정규화를 진행하면 데이터가 아래와 같이 분리되며, 각 그룹의 흐름은 다음 설명과 같습니다.
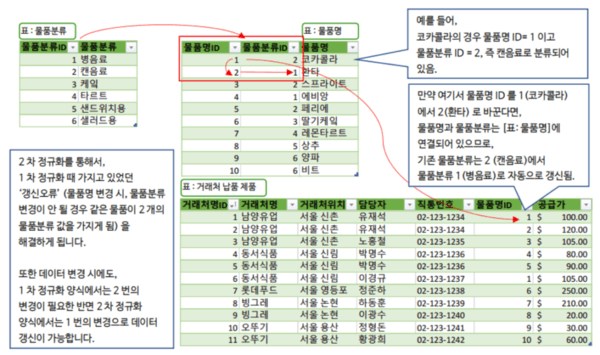
3-B. 데이터 처리 과정의 3단계
이전 강의에서 말씀드린 것처럼, 데이터 처리 과정은 삽입·변경·삭제의 3단계로 이루어집니다.
- 데이터 삽입 시 발생하는 문제 : 1차 정규화로 해결
- 데이터 변경 시 발생하는 문제 : 2차 정규화로 해결
다만 "데이터 삭제 단계의 문제는 2차 정규화만으로는 완전히 해결되지 않습니다." 아래 예제와 함께 살펴봅니다.
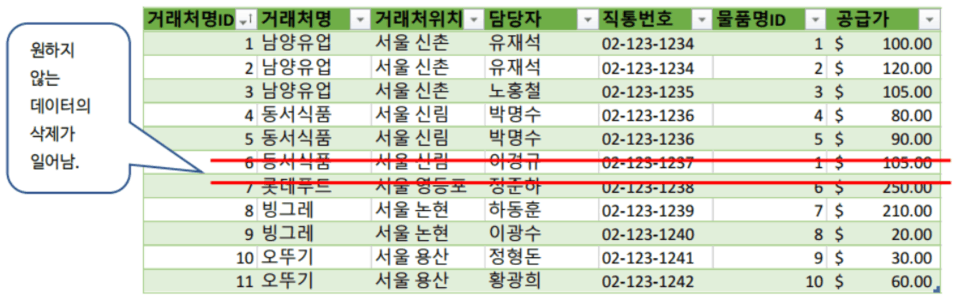
3-C. 데이터 삭제 시 발생하는 문제
예를 들어, 동서식품에서 코카콜라를 더 이상 납품받지 않게 되어 거래처명ID 6번 항목을 삭제한다고 가정해봅니다.
이 경우 동서식품의 코카콜라 항목만 삭제하려고 했지만, 회사에서 정상 근무 중인 '이경규' 직원의 데이터까지 함께 삭제되는 문제가 발생합니다.
같은 원리로, 7번 항목인 롯데푸드의 데이터를 삭제하면 거래처 정보와 함께 정준하 직원의 데이터도 동시에 사라지게 됩니다.
3차 정규화는 '독립적인' 데이터를 그룹으로 묶어 각각 다른 테이블로 분리하는 작업입니다. 3차 정규화까지 마무리한 표는 다음과 같습니다.
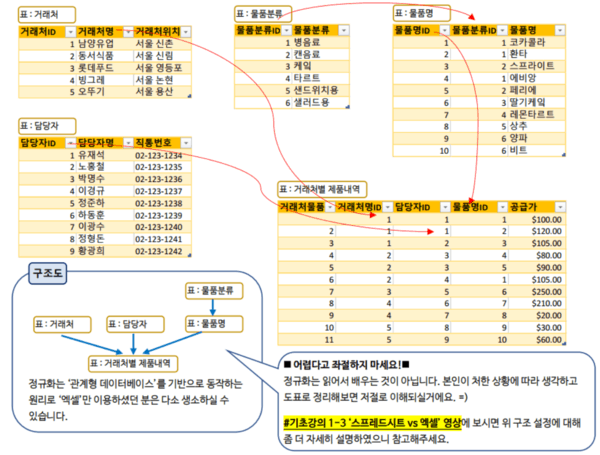
Q] 독립적인 데이터를 분리하는 이유는 무엇인가요?
지금 다루고 있는 데이터의 목적은 '거래처별로 납품받는 제품을 각 회사 담당자별로 구분'하는 것입니다. 따라서 이 데이터에는 총 3개의 데이터 그룹이 필요합니다.
- 거래처별 데이터
- 제품별 데이터
- 담당자별 데이터
위 3개의 데이터 그룹은 서로 독립적으로 존재하고, 그중 제품별 데이터에서는 물품분류와 물품명이 종속 관계를 가집니다.
만약 거래처별로 '제빵류 거래처', '음료수 거래처'처럼 별도의 거래처 구분을 둔다면, 거래처 구분 역시 거래처명과 종속 관계를 가지게 됩니다.
이렇게 데이터를 독립적으로 분리하면 관리가 훨씬 수월해질 뿐 아니라, 전체 파일 크기도 함께 줄어드는 장점이 있습니다.

=LOOKUP([@물품명ID],tbl물품명[#All],3) -> 어디가 잘 못되었나요?
뒤에 3은 어떤 목적으로 넣으신건가요?