

ChatGPT 프롬프트 엔지니어링 실전 가이드
인컨텍스트 학습과 역할 부여, 퓨샷, RAG, COT 기법까지 ChatGPT 프롬프트 엔지니어링의 핵심 원리와 활용법을 단계별로 정리합니다.
이 강의에서는 ChatGPT를 실무에서 더 정확하게 활용하기 위한 프롬프트 엔지니어링의 핵심 원리를 다룹니다. 모든 기법의 바탕이 되는 인컨텍스트 학습 개념부터 역할 부여, 명확한 지시, 환각 현상을 줄이는 RAG, 단계적 사고를 끌어내는 COT 기법까지 순서대로 살펴봅니다. ChatGPT의 답변 품질을 끌어올리고 싶은 직장인이라면 일관된 결과를 만드는 기준을 세울 수 있습니다.

목차 보기






ChatGPT의 모든 답변을 좌우하는 인컨텍스트 러닝
ChatGPT를 비롯한 LLM은 거의 대부분 인컨텍스트 러닝(In-Context Learning) 방식으로 동작합니다. 사용자가 채팅창에 입력한 정보와 이전 대화의 흐름을 보고 다음 응답을 만들어내는 구조이기 때문에, 어떤 맥락을 어떻게 제공했는지가 결과의 품질을 결정합니다.
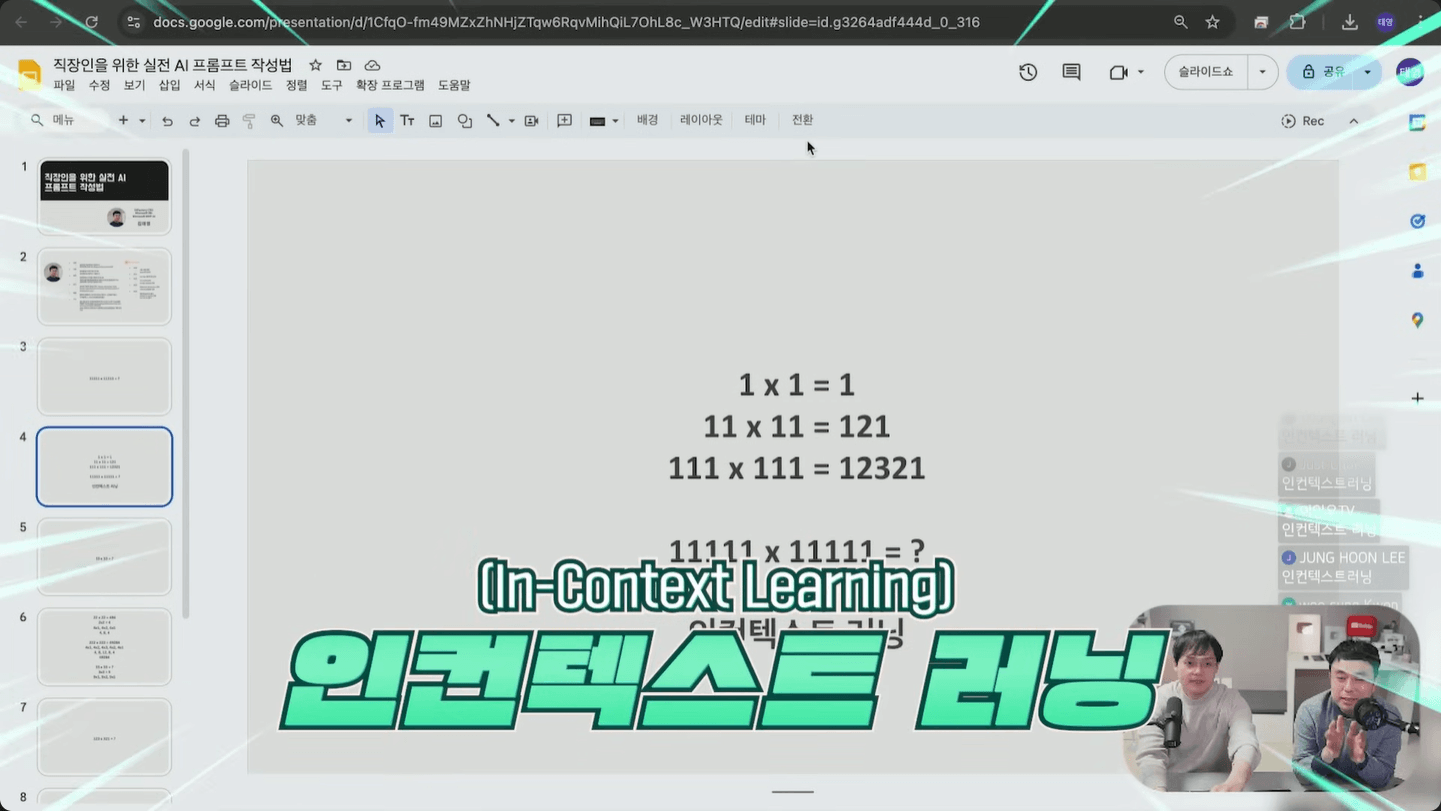
강의에서는 11111×11111 같은 곱셈을 예로 알아봤습니다. 이 곱셈을 처음 접한다면 한 번에 답을 떠올리기는 어렵지만, 1이 5개 곱하기 1이 5개의 결과, 1이 7개 곱하기 1이 7개의 결과를 차례로 알려주면 패턴을 잡아 쉽게 답을 맞출 수 있습니다.

ChatGPT가 답변하는 방식도 이와 같아서, 이전에 어떤 맥락을 줬는지가 다음 답변에 그대로 반영됩니다.
- 모든 프롬프트 기법은 인컨텍스트 러닝의 응용입니다. 역할 부여, 퓨샷, RAG, COT 모두 결국 어떤 맥락을 어떻게 입력하느냐의 문제로 귀결됩니다.
- 같은 질문이라도 이전 대화에서 어떤 정보가 오갔는지에 따라 답변이 달라지므로, 같은 채팅 세션 안에서는 흐름을 의식적으로 관리해야 합니다.
- 새 채팅을 시작하면 이전 맥락은 모두 초기화됩니다. 화자는 새로운 사람으로 태어나 다시 대화하는 것이라고 표현합니다.
내가 원하는 것을 짧은 프롬프트 안에 얼마나 잘 알려줬는가가 프롬프트 엔지니어링의 핵심이며, 이 한 가지 원칙만 잡아도 답변 품질이 절반 이상 올라갑니다.
원하는 대화 흐름을 시스템 프롬프트로 이어가는 방법
같은 채팅에서 만족스러운 답변이 나왔다면 그 흐름을 다음 작업에도 이어가고 싶어집니다. 이때 이전 대화를 그대로 복사해 새 채팅에 붙여 넣을 수도 있지만, 더 깔끔한 방법은 ChatGPT 본인에게 시스템 프롬프트를 작성하게 하는 것입니다.
- 지금까지의 대화가 마음에 들었다면 ChatGPT에 지금까지의 대화 내용이 좋았으니 앞으로 같은 방식으로 대답하도록 시스템 프롬프트를 작성해 달라고 요청합니다. 마치 퇴사하는 직원이 후임자에게 인수인계서를 정리해 주는 것과 같은 구조입니다.
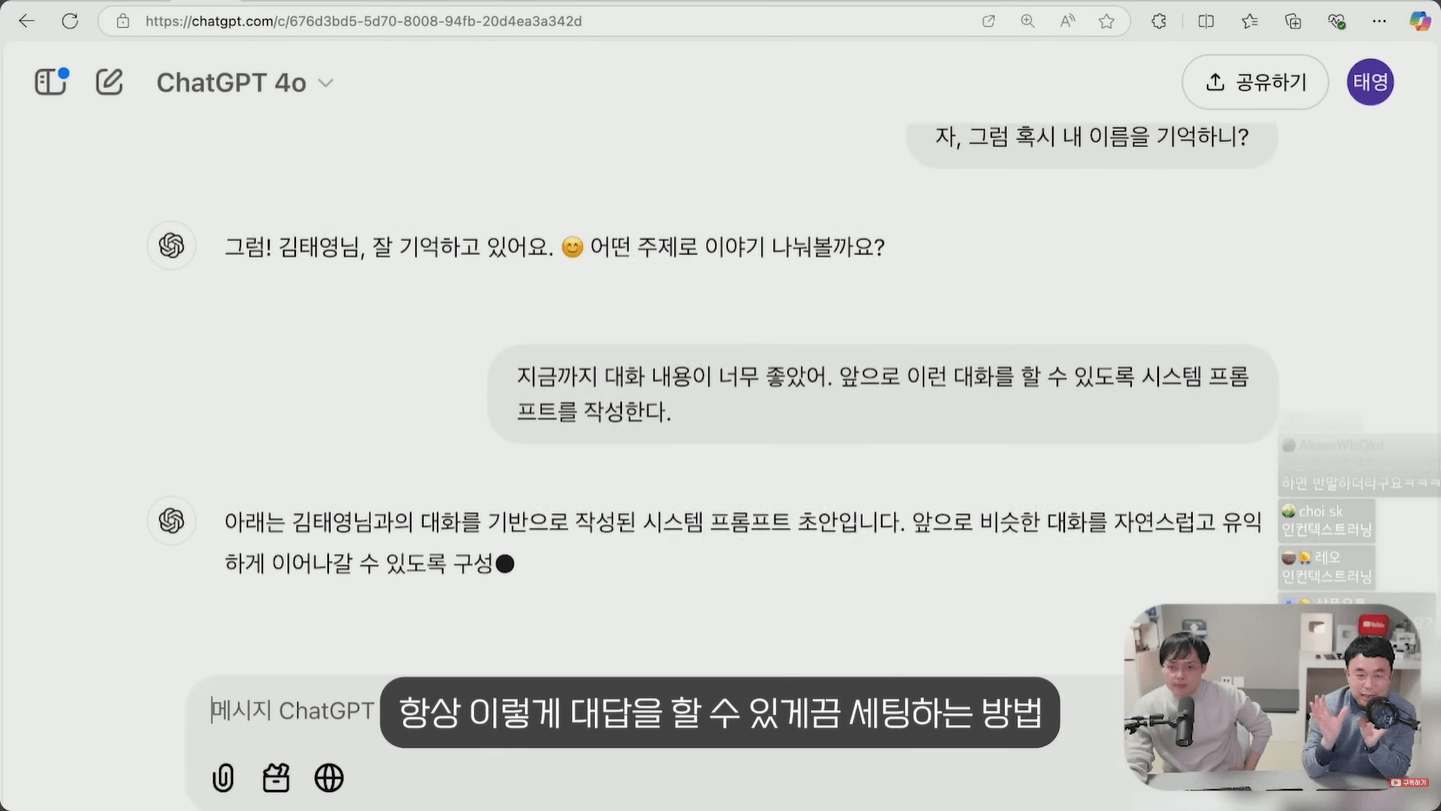
- 받은 시스템 프롬프트를 새 채팅의 첫 입력으로 사용합니다. 이렇게 하면 이전의 모든 대화를 다시 붙여 넣지 않아도 같은 응답 톤과 형식을 유지할 수 있습니다.
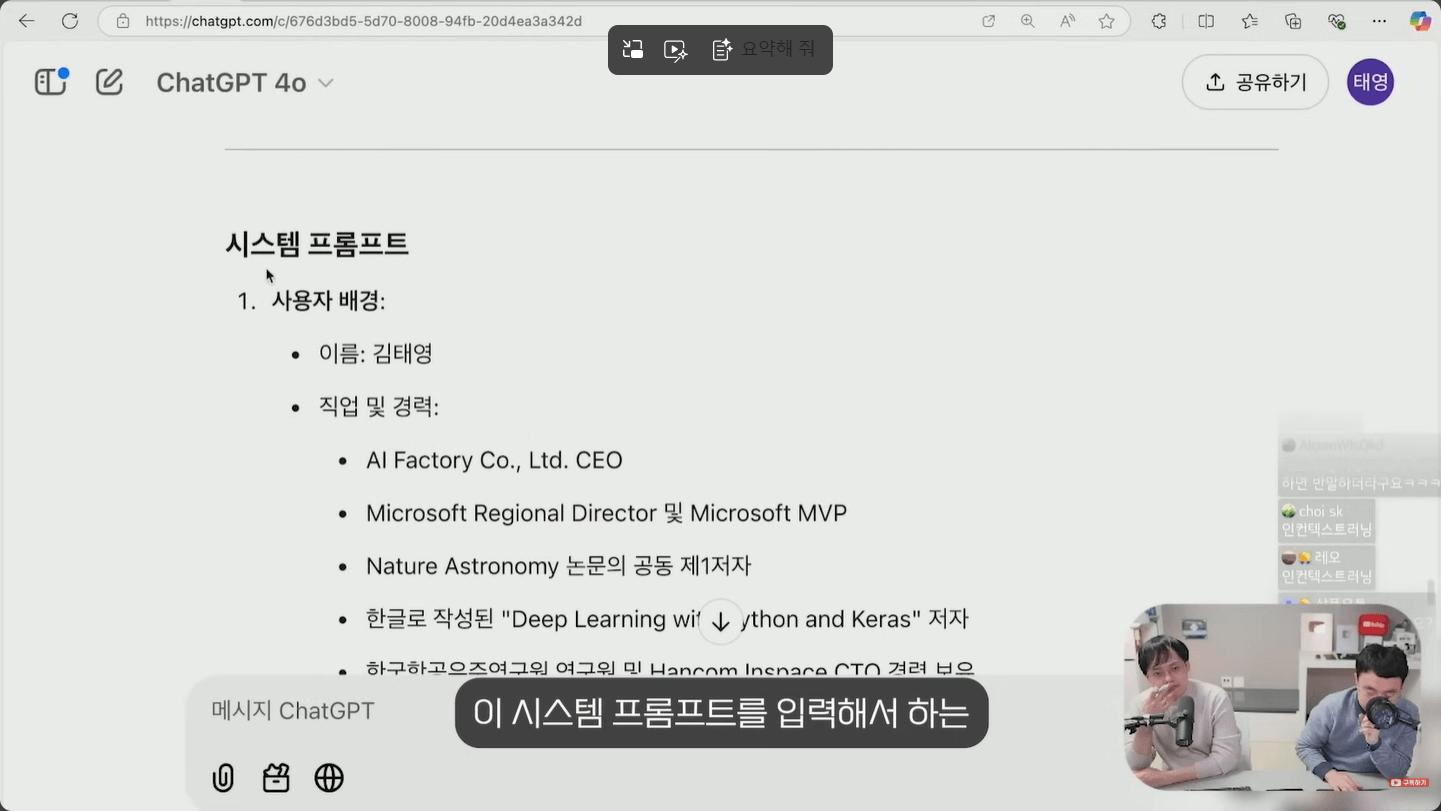
- 대화 중간에 잘못된 정보가 섞이면 이후 답변에 부정적인 영향을 줍니다. 엑셀 이야기를 하던 중 구글 시트 이야기가 잠시 들어가면, 다음에 SUM 함수를 물었을 때 갑자기 구글 시트 기준으로 답할 수 있습니다.
- 잘못된 흐름이 생겼다면 ChatGPT 메시지의 편집(연필) 버튼으로 해당 질문을 수정해 분기를 새로 만들 수 있습니다. 로그인한 사용자만 사용 가능한 기능이며, 분기마다 페이지 넘김 화살표가 생겨 원하는 흐름으로 다시 진입할 수 있습니다.
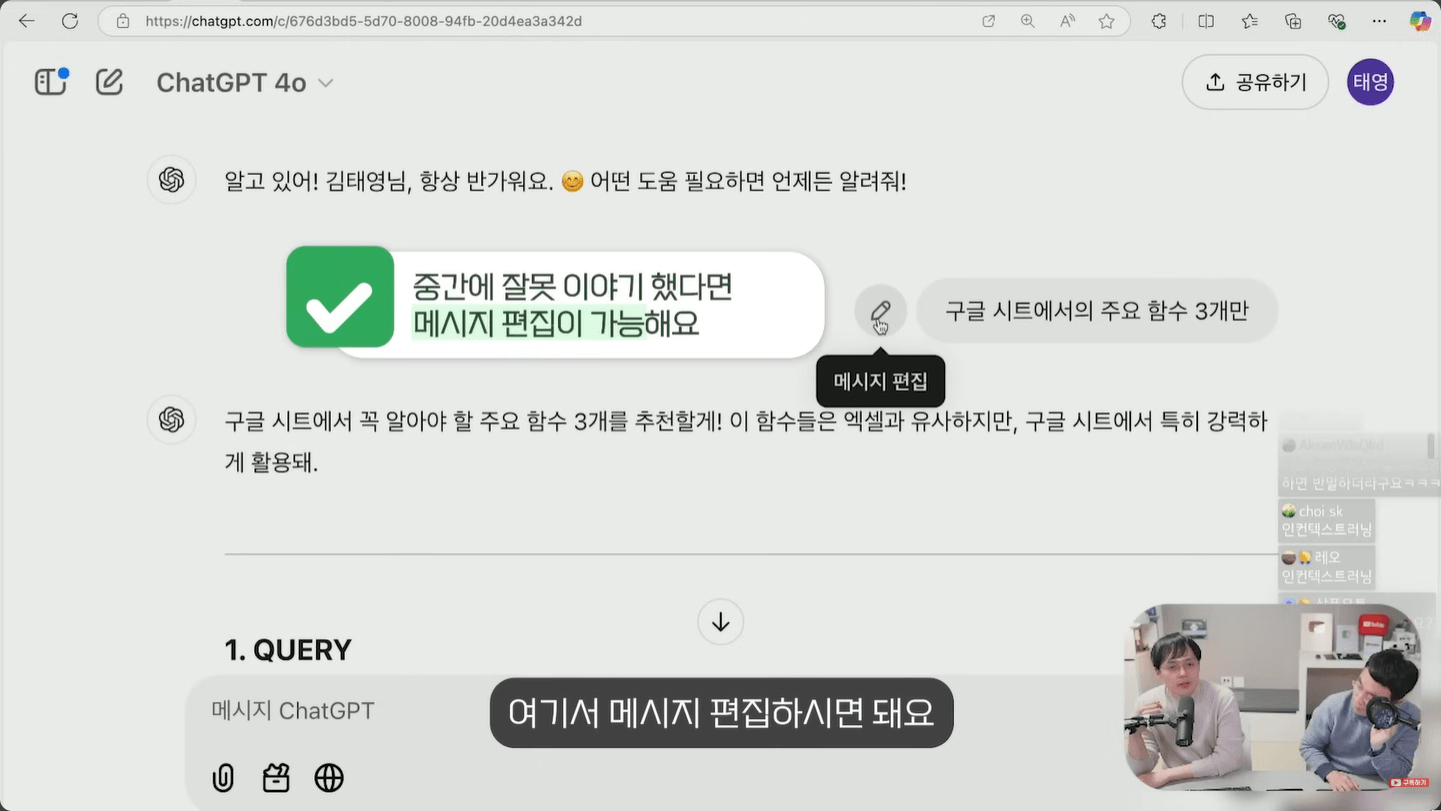
- 대화 중간에 좋아, 잘했어 같은 칭찬과 이 페이지의 이 문단이 마음에 들지 않는다 같은 구체적인 지적을 함께 사용합니다. 칭찬은 ChatGPT가 사용자의 선호를 파악하는 가장 큰 신호이며, 구체적인 피드백은 다음 응답의 방향을 잡아 줍니다.
피드백을 줄 때는 다시 해 와 같은 추상적인 명령이 아니라 어떤 부분이 왜 부족한지 짚어줘야 합니다. 피드백의 구체성이 곧 다음 답변의 정확도가 됩니다.
역할 부여와 명확한 지시로 답변 정확도 높이기
프롬프트 엔지니어링에서 가장 강력한 도구는 역할 부여(Role Prompting)입니다. ChatGPT와 사용자가 둘 다 알고 있는 단어 하나로 길게 설명할 내용을 함축할 수 있기 때문입니다.
강의에서는 채널 구독자라는 한 단어로 청중 특성을 모두 전달하는 사례를 보여줍니다. ChatGPT는 이미 인터넷에서 해당 채널 구독자에 대한 정보를 학습해 두었기 때문에, 반복 업무를 줄이고 자기주도적으로 문제를 해결하는 일잘러라는 묘사를 부연 설명 없이 끌어냅니다.
- 역할 부여는 너는 ~이다 보다 ~처럼 행동해 형태가 더 효과적입니다. 너는 ~이다 라고 하면 ChatGPT가 본래의 정체성과 충돌해 거부할 수 있지만, ~처럼 행동해는 일시적인 페르소나 모드로 받아들이기 때문입니다.
- 역할에 사용하는 단어는 전문 용어일수록 좋습니다. 조건부서식 한 단어가 어떤 상황에 따라 보이는 것을 다르게 할 수 있는 기능이라는 긴 설명을 대신해 줍니다. 전문 용어 안에 이론적 배경이 함께 담겨 있기 때문입니다.
- 지시문을 작성할 때는 ChatGPT와 사용자가 같은 단어를 알고 있는지 먼저 확인합니다. 사용자 정의 함수처럼 화자만 아는 용어가 있다면 이전 대화에서 정의를 알려주고 사용해야 합니다.
- 유치원생에게 알파벳 단어를 정렬해 달라고 했을 때 알파벳이 아니라 정렬이라는 개념을 몰라서 못 하는 것과 같습니다. ChatGPT가 모르는 단어를 사용할 때는 정의부터 입력으로 함께 넣어 줍니다.
- 퓨샷(Few-shot) 프롬프팅은 원하는 출력 형식을 예시로 보여주는 방식입니다. 답변 끝에 1입니다, 2입니다 같은 형식을 한두 개 보여주면 이후 모든 응답이 같은 형식으로 정렬되며, 회계점 표기 같은 세부 양식도 그대로 따라옵니다.
- 예시는 많을수록 좋습니다. 하나만 주면 부족하고, 서너 개 이상을 주면 패턴이 안정적으로 잡힙니다. 예시가 곧 가장 명확한 지시이기 때문입니다.
할루시네이션을 줄이는 검색 결과 기반 프롬프팅
ChatGPT는 학습 데이터에 없는 주제에 대해서도 그럴듯한 답변을 만들어 내는 경우가 있습니다. 강의에서는 가상의 2027년 자율주행 회사에 대한 질문에 ChatGPT가 사실처럼 답변하는 모습을 보여줍니다. 이것이 환각(Hallucination, 할루시네이션) 현상입니다.
할루시네이션을 줄이는 가장 확실한 방법은 답변의 근거가 될 정보를 사용자가 직접 입력으로 넣어주는 것입니다.
- 먼저 ChatGPT에 역할을 부여합니다. 너는 훌륭한 비서처럼 행동해 라는 한 줄로 답변 톤과 자세를 설정합니다.
- 아래 검색 결과를 바탕으로 질문에 답변한다 라는 지시를 명확하게 적습니다. ChatGPT가 자기 지식이 아닌 입력된 자료에서만 답을 찾도록 유도하는 핵심 문장입니다.
- 대괄호로 검색 결과 시작과 검색 결과 끝 구간을 만들고 그 사이를 비워 둡니다. 수능 지문 형식과 같이 다음 지문을 읽고 답변하시오 구조를 만드는 단계입니다.
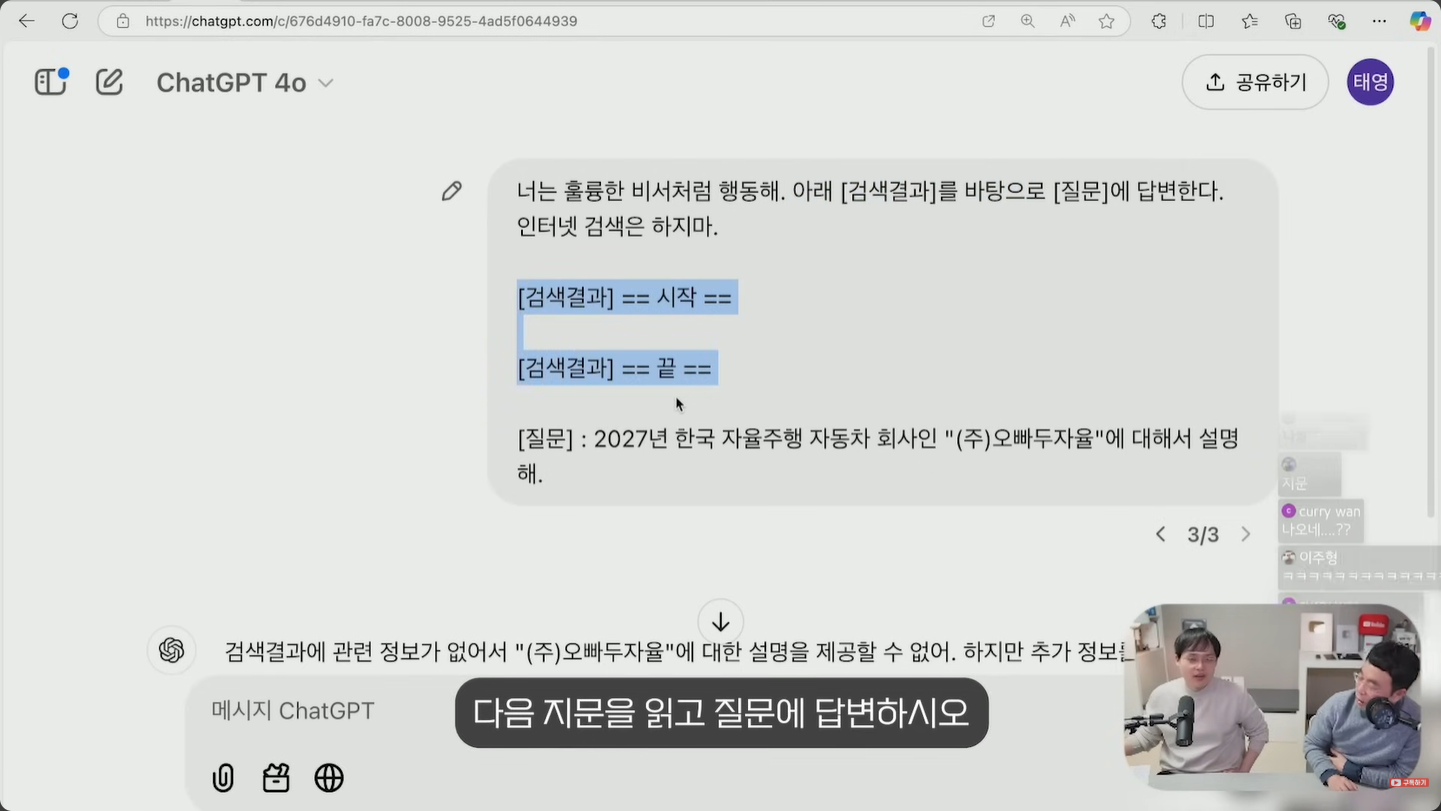
- 검색 결과가 비어 있는 상태에서 질문하면 ChatGPT는 관련된 정보가 없어 답변을 제공할 수 없다고 응답합니다. 이 상태가 환각이 일어나지 않는 안전한 출발점입니다.
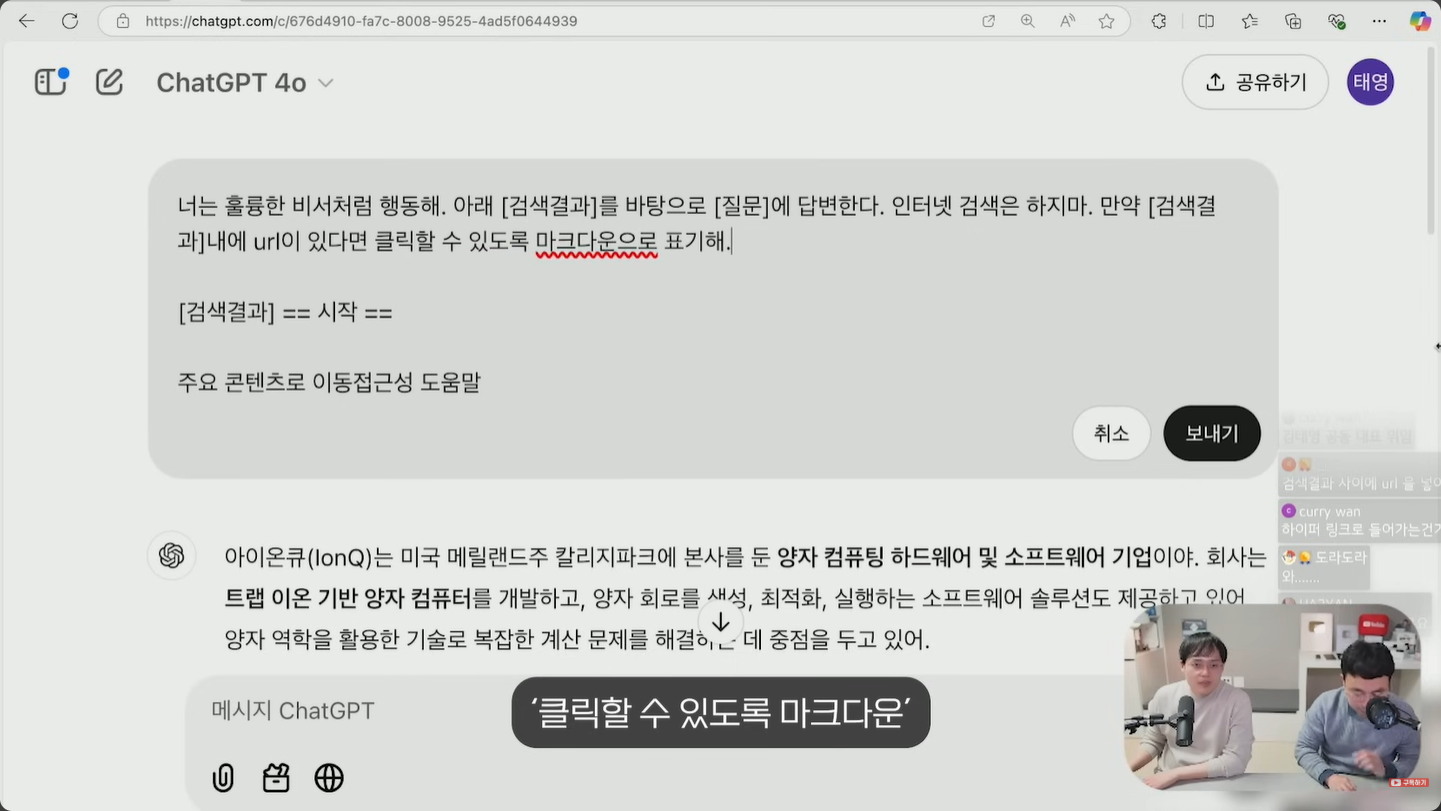
- 인터넷 검색은 하지 마 라는 단서를 함께 넣어 두면 ChatGPT가 임의로 외부 정보를 가져오는 것을 차단합니다.
- 이제 검색 결과 구간에 신뢰할 만한 출처에서 가져온 정보를 붙여 넣습니다. 구글 검색 결과 페이지를 통째로 복사해 붙여도 LLM이 요약에 능하기 때문에 필요한 정보만 골라 답합니다.
- 검색 결과 내에 URL이 있다면 클릭할 수 있도록 마크다운으로 표시해 달라는 옵션을 추가하면 출처 링크가 함께 정리된 결과를 받을 수 있습니다.
텍스트 복사 붙여넣기 대신 PDF나 한글 파일을 PDF로 변환해 첨부하는 방식도 가능합니다. 이때는 첨부된 파일을 바탕으로 라고 지시하며, 대괄호 구간은 생략해도 됩니다. 파일이 여러 개일 때는 모두 업로드한 뒤 특정 파일 이름을 지정해 집중적으로 참고하도록 요청할 수 있습니다.
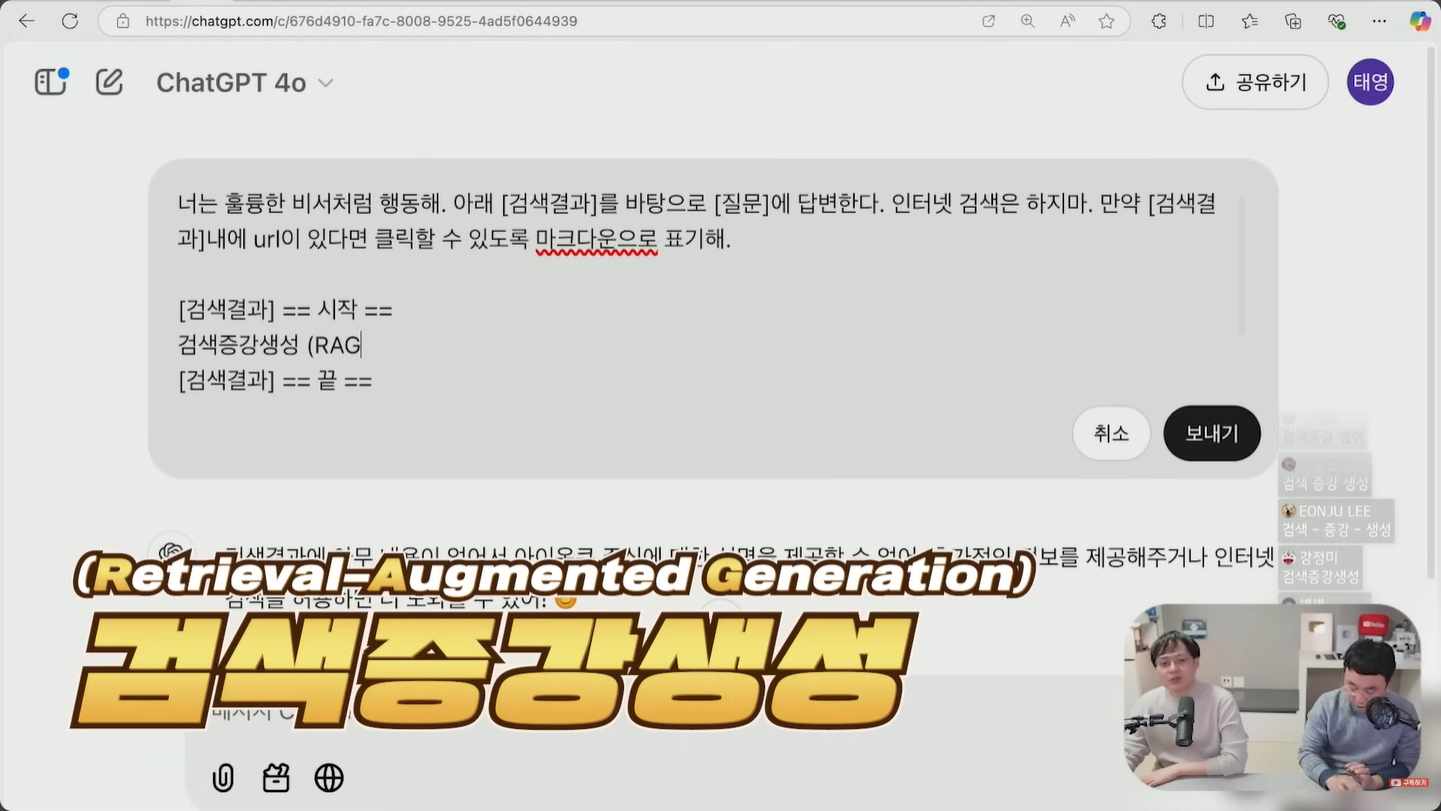
검색 증강 생성(RAG)이 중요해지는 이유
앞서 살펴본 검색 결과를 직접 넣어주고 그 안에서만 답하게 하는 방식이 바로 검색 증강 생성, RAG(Retrieval-Augmented Generation)입니다. Retrieval(검색·회수), Augmented(증강), Generation(생성)의 머리글자를 딴 용어이며, 작년부터 LLM 분야에서 가장 뜨거운 키워드로 자리 잡았습니다.
핵심은 단순합니다. 지문으로 답변하는 구조가 RAG의 본질이며, 이 한 가지만 이해해도 RAG 사용 원리를 다 이해한 것과 같습니다. 사용자가 매번 검색 결과를 직접 붙여 넣을 필요 없이 시스템이 자동으로 자료를 찾아 프롬프트에 합쳐 주는 도구가 점점 늘어나고 있습니다.
- Perplexity 같은 검색 기반 AI 서비스는 사용자 눈에는 보이지 않지만 내부적으로 다음 인터넷 검색 결과를 넣어줄 테니 그 기반으로 답변해 달라는 RAG 구조가 숨겨져 있습니다.
- ChatGPT의 웹 검색 기능 역시 동일한 원리로 동작합니다. 모델이 직접 인터넷을 떠도는 것이 아니라, 검색 결과를 회수해 프롬프트에 합친 뒤 답변을 생성합니다.
- 이미 잘 알려진 주제라면 시스템이 인터넷 검색이 필요 없다고 판단해 학습된 지식만으로 답하는 경우도 있습니다. 사용자가 일일이 지시하지 않아도 도구가 알아서 RAG 사용 여부를 결정합니다.
- 실무에서 신년 기획서를 쓸 때는 작년 보고서 PDF와 인터넷에서 찾은 내년 전망 자료를 함께 첨부하고 이 자료를 기반으로 제안서를 작성해 달라고 요청하면 환각 없이 사실 기반의 초안을 얻을 수 있습니다.
- 주식 분석 같은 시의성 있는 작업에는 최신 뉴스 본문을 그대로 복사해 프롬프트에 넣고 분석을 요청합니다. ChatGPT는 어제까지의 사건을 모르지만, 입력으로 들어온 정보 안에서는 정확하게 답할 수 있습니다.
퓨샷이든 RAG든 결국 모두 인컨텍스트 러닝의 응용입니다. 내가 어떤 정보를 어떻게 컨텍스트에 넣었는가가 모든 프롬프트 기법의 출발점이라는 사실을 기억하면 새로운 기법이 나와도 빠르게 이해할 수 있습니다.
단계적 사고로 정확도를 끌어올리는 COT 기법
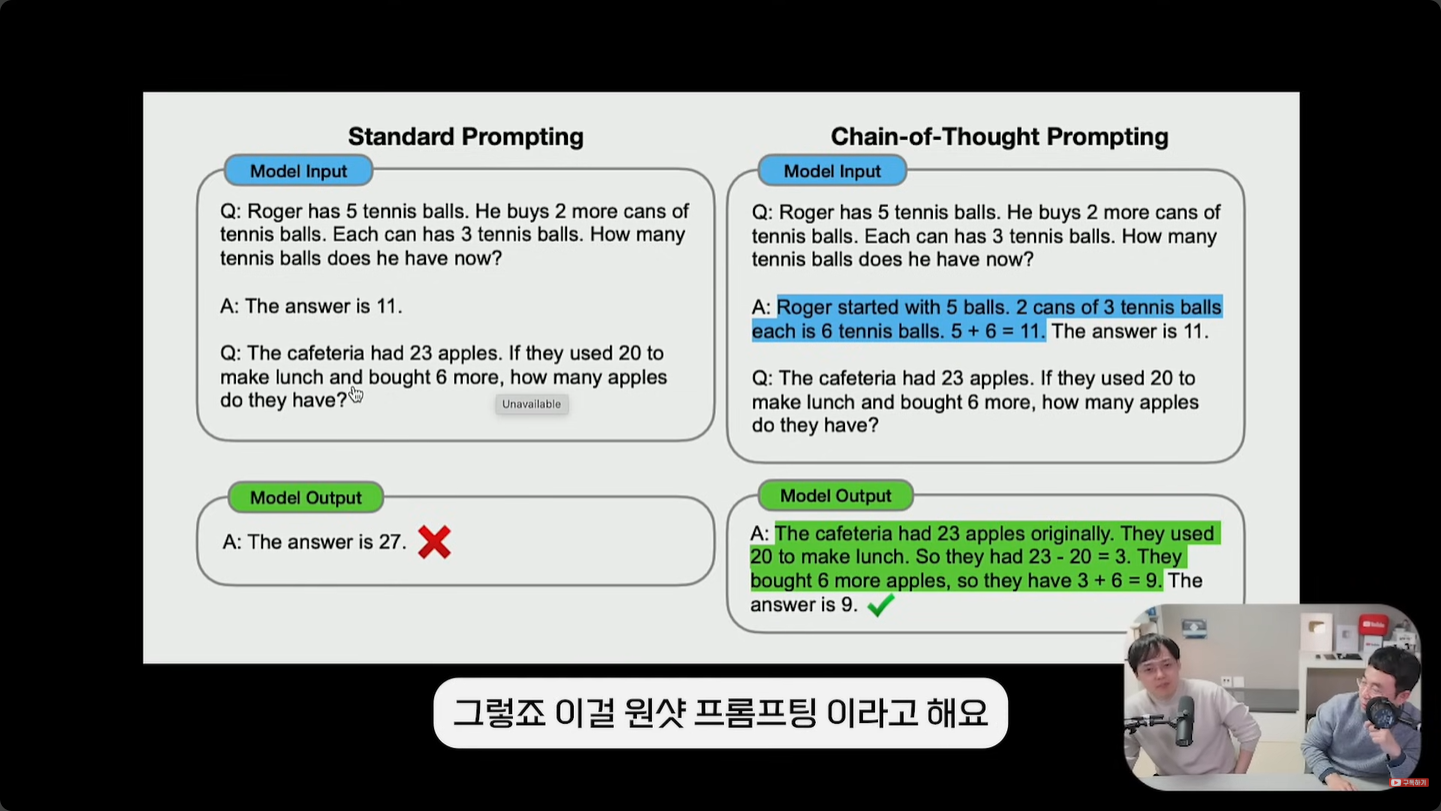
COT(Chain of Thought, 생각의 사슬)는 ChatGPT에 답만 요구하지 않고 풀이 과정을 함께 작성하게 만드는 기법입니다. 단순한 한 줄을 추가하는 것만으로 답변의 정확도가 크게 올라가, COT 논문 발표 이후 LLM 분야의 큰 파도를 만든 핵심 기법입니다.

강의 도입부의 11111×11111 예시를 다시 보면, 사람도 처음에는 한 번에 답을 못 했지만 단계별로 풀이 과정을 보여주자 패턴을 잡아 답을 맞췄습니다. ChatGPT 역시 풀이 과정을 적게 하면 단순히 답만 추측할 때보다 훨씬 정확한 결과를 만듭니다.
- 퓨샷 프롬프팅에서 예시를 줄 때 답만 적지 말고 풀이 과정을 함께 적어 줍니다. 예시 자체가 이런 식으로 단계를 밟아 답하라는 신호가 되어, 이후 질문에도 ChatGPT가 풀이 과정을 적으면서 답하게 됩니다.
- 예시가 전혀 없는 상황에서는 제로샷 COT를 사용합니다. 프롬프트 끝에 Let's think step by step(차근차근 생각해 보자) 한 문장을 추가하기만 하면 됩니다. 이 한 줄이 모든 프롬프트의 성능을 향상시킨다는 사실이 논문으로 입증되어 있습니다.
- 부장이 부하 직원에게 올해 매출을 예상해 달라고 묻는 상황과 비교할 수 있습니다. 작년 계획 10억, 분기별 실적, 실제 12억 마감이라는 맥락을 함께 주면 부하 직원이 막연히 20억이라고 답하지 못하고 분기별 추세를 반영해 답하게 됩니다. ChatGPT도 마찬가지입니다.
- o1 계열 모델은 COT 기법이 모델 자체에 강화학습으로 내장된 모델입니다. 사용자가 생각의 사슬을 명시하지 않아도 입력 직후 생각 중 단계가 표시되며, 충분히 사고한 뒤에 답변을 시작합니다.
- o1 pro mode는 더 깊은 사고를 수행해 응답에 시간이 더 걸리지만, 내부적으로 수백 가지의 후보 응답을 비교한 뒤 최적의 답을 골라 줍니다. 닥터 스트레인지가 여러 시간대를 훑어보고 최고의 결과를 고르는 것과 비슷한 구조입니다.
- 2025년에는 후속 모델 o3가 발표될 예정이며, 코딩 92% 박사과정 문제 87% 수준의 성능이 보고되고 있습니다. 발표 주기가 몇 달 단위로 짧아지고 있기 때문에 후속 모델은 더 빠르게 등장할 가능성이 높습니다.
- ChatGPT 좌측의 맞춤 설정 메뉴에서 메모리 항목에 들어가면 그동안의 대화에서 저장된 정보를 관리할 수 있습니다. LLM 자체가 기억하는 것이 아니라, DB에 저장된 메모리가 매 요청마다 프롬프트에 자동으로 합쳐지는 구조입니다. 기억해 라고 지시하면 Function Calling을 통해 메모리에 새 항목이 등록됩니다.
여러 사람이 한 ChatGPT 계정을 공유하거나 다양한 주제로 사용한다면 메모리 기능은 끄는 편이 안전합니다. 한 주제의 설정이 다른 주제 응답에 영향을 줘 갑자기 반말이 나오는 등의 의도치 않은 결과가 생길 수 있기 때문입니다.
