

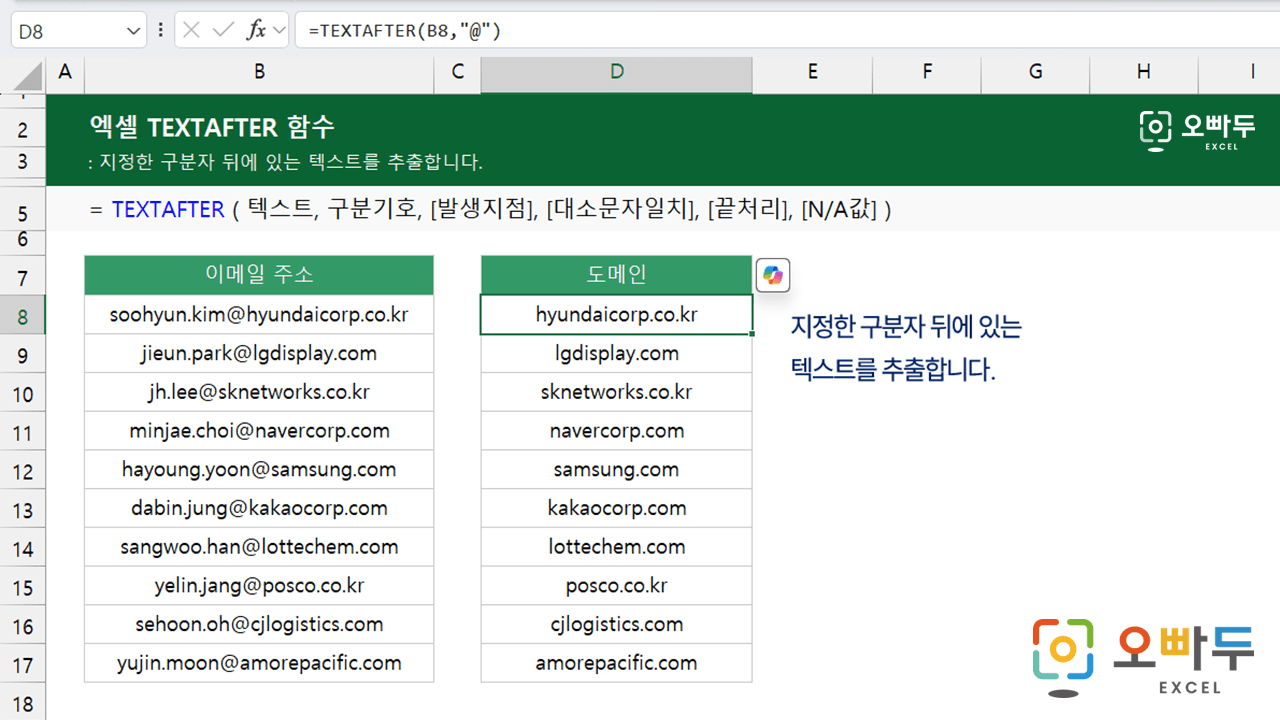
엑셀 TEXTAFTER 함수는 지정한 구분자 뒤에 있는 텍스트를 추출하는 함수입니다.
=TEXTAFTER(텍스트, 구분기호, [발생지점], [대소문자일치], [끝처리], [N/A값])
- 중괄호 {} 로 묶어 여러 구분기호를 사용할 수 있습니다.
=TEXTAFTER(텍스트,{"@","/"}) → "@"와 "/" 를 구분기호로 사용합니다.
- 기본값은 1 입니다. 음수로 입력하면 뒤에서부터 셉니다.
예) -1 : 뒤에서 첫번째로 발생하는 기호를 기준으로 나눕니다.
- 0 [기본값] : 대소문자를 구분합니다.
- 1 : 대소문자를 구분하지 않습니다.
- 0 [기본값] : 처리하지 않음
- 1 : 텍스트 끝을 구분기호로 처리
엑셀 TEXTAFTER 함수는 문장에서 특정 구분자 뒤에 있는 텍스트를 추출하는 함수입니다. 예를 들어, 이메일(abc@naver.com)에서 "@" 뒤에 있는 "naver.com" 을 추출하거나 "김하늘/45세"로 작성된 문장에서 "/" 뒤에 있는 "45세"를 추출할 때 사용할 수 있습니다.
=TEXTAFTER("abc@naver.com","@")/ / → "naver.com" =TEXTAFTER("김하늘/45세","/")/ / → "45세"
엑셀 이전 버전에서는 텍스트의 특정 부분을 추출하려면 FIND 함수나 SEARCH 함수로 원하는 위치를 찾은 후, MID 함수나 RIGHT 함수를 결합해 복잡한 공식을 만들어야 했으나 TEXTAFTER 함수를 사용하면 간단하게 구분자 뒤의 텍스트를 추출할 수 있습니다. 구분자 앞의 텍스트를 추출하려면 TEXTBEFORE 함수를 사용합니다.
다음과 같이 함수를 작성하면 이메일 주소에서 "@" 뒤의 도메인을 추출할 수 있습니다.
=TEXTAFTER("Kim.SY@naver.com","@") / / "naver.com" 을 추출합니다.
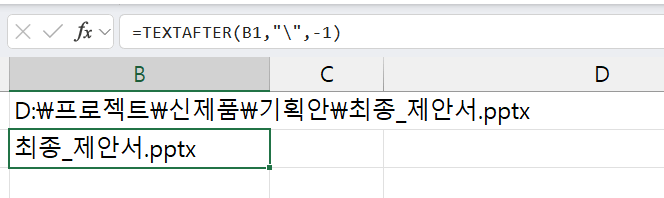
다음과 같이 TEXAFTER 함수를 사용하면 전체 파일 경로에서 마지막으로 발생한 "\" 를 기준으로 파일명을 추출할 수 있습니다.
=TEXTAFTER("D:\프로젝트\신제품\기획안\최종_제안서.pptx","\",-1) / / "최종_제안서.pptx" 를 추출합니다.
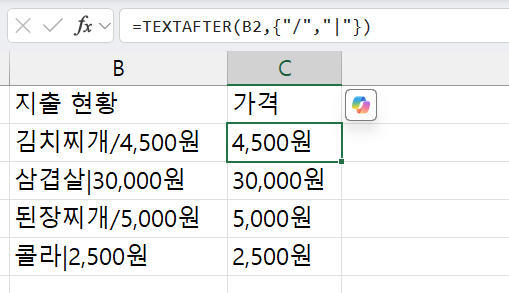
다음과 같이 함수를 작성하면 여러 개의 구분기호를 기준으로 텍스트를 나눌 수 있습니다.
=TEXTAFTER("김치찌개/4,500원",{"/","|"}) =TEXTAFTER("삼겹살|30,000원",{"/","|"}) / / 문장에서 "/" 와 "|" 기준으로 뒤에 있는 텍스트를 추출합니다.
[끝처리] 인수는 문자열의 끝 부분을 가상의 구분자로 처리함으로서, 발생 지점으로 문자열을 추출할 때 오류를 예방하는 안전 장치로 사용할 수 있습니다. 예를 들어 "강남_아이파크_102동_4호" 라는 문자열에서 "_" 기호를 기준으로 TEXTAFTER 함수를 사용하는 상황을 가정하겠습니다.
=TEXTAFTER("강남_아이파크_102동_4호","_",-2) / / 뒤에서 2번째 구분자 기준 뒤에 있는 "102동_4호"를 추출합니다. =TEXTAFTER("강남_아이파크_102동_4호","_",-3) / / 뒤에서 3번째 구분자 기준 뒤에 있는 "아이파크_102동_4호"를 추출합니다. =TEXTAFTER("강남_아이파크_102동_4호","_",4) / / 4번째 구분기호가 없으므로 #N/A 오류를 반환합니다.
하지만 끝처리를 1로 입력하면 텍스트 끝에 가상의 구분기호가 추가되어, 문자열에 구분기호가 없거나 발생지점이 잘못되더라도 전체 문자열을 반환할 수 있습니다.
=TEXTAFTER("강남_아이파크_102동_4호","_",-4,,1) / / 텍스트 끝에 가상의 구분기호가 추가되어 "강남_아이파크_102동_4호"를 반환합니다.