

엑셀 in 파이썬, 공식 업데이트! 기초-활용 20분 총정리
드디어, 엑셀에 파이썬이 정식으로 공개되었습니다! 다양한 데이터 분석 툴을 실무에 바로 적용해보세요!
이 강의에서는 M365 베타 버전에 도입된 엑셀 Python 기능의 사용법을 다룹니다. =py() 함수로 편집기를 실행하는 기본 조작부터 DataFrame을 활용한 데이터 분석, query·pivot_table·plot 함수로 만드는 자동화 보고서, regex 라이브러리로 비정제 데이터를 가공하고 실시간 주식 차트를 작성하는 실무 예제까지 정리합니다.

실습자료를 준비했어요
수업에서 사용한 예제 파일과 보충 자료를 한 곳에 정리했습니다!👇
목차 보기
![[2025 최신] 엑셀 코파일럿 + 파이썬 완벽 가이드 | 직장인 데이터 분석 실전 예제](https://www.oppadu.com/wp-content/uploads/2020/06/엑셀-파이썬-분석-자동화-썸네일_R.png)





엑셀 Python 기능 소개 (베타 버전 기준, 장단점)
2023년 8월 22일부터 M365 베타 버전 사용자를 대상으로 엑셀의 Python 기능이 순차적으로 배포되기 시작했습니다. 2023년 9월 현재 2310 버전(빌드 16907 이상) 사용자는 엑셀에서 Python 기능을 바로 사용할 수 있습니다.
엑셀 Python 기능은 ① MS 클라우드에서 동작하며, Python 핵심 패키지인 ② 아나콘다(Anaconda)를 기본으로 제공합니다. 따라서 별도의 Python 프로그램을 설치하지 않아도 누구나 손쉽게 활용할 수 있습니다. 다만 사용할 수 있는 라이브러리가 ③ 아나콘다 패키지에서 제공하는 라이브러리로 제한된다는 단점이 있습니다.

① 별도의 프로그램을 설치하지 않아도 엑셀에서 Python을 편리하게 사용할 수 있습니다.
② MS에서 보안을 철저히 관리하므로 외부의 해킹 위협으로부터 상대적으로 안전하게 사용할 수 있습니다.
③ 클라우드에서 동작하므로 PC 자원을 절약하면서 안정적으로 Python 코드를 실행할 수 있습니다.
① 사용할 수 있는 라이브러리가 'Anaconda'에서 제공하는 라이브러리로 제한됩니다.
② 클라우드에서 동작하기 때문에 사용자 PC에서 파일을 저장하거나 메일을 발송하는 등의 직접적인 업무 자동화는 구현이 불가능합니다.
③ 대용량 데이터(수만 행 이상)로 차트 이미지를 출력할 경우 처리 속도가 느린 편이지만, 추후 개선될 것으로 보입니다.
엑셀 Python 기능 기본 사용법
엑셀 Python 기능 사용법은 매우 간단하며, 다음 3가지 방법으로 Python 코드 편집기를 실행할 수 있습니다.
방법① : 셀 안에 "=py()"로 py 함수 입력
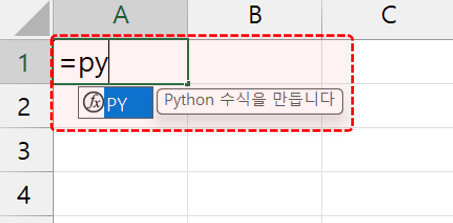
방법② : [수식] 탭 - [Python 삽입] 버튼 클릭

방법③ : 단축키 Ctrl + Alt + Shift + P 동시 입력
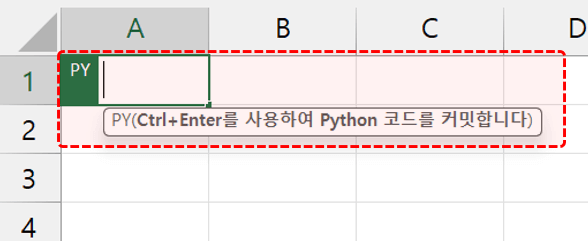
Python 편집기를 실행한 뒤 코드를 작성하면 엑셀에서 Python을 바로 사용할 수 있습니다. 편집기에서 Enter 키를 누르면 줄바꿈이 추가되며, Ctrl + Enter 를 동시에 입력하면 작성한 Python 코드를 실행할 수 있습니다.


엑셀 Python 기본기 다지기
가장 쉬운 예제로 엑셀에 작성된 범위를 Python으로 출력하는 방법부터 살펴보겠습니다.
- 범위를 DataFrame으로 변환하기 : 예제파일을 실행한 뒤 [엑셀xPython] 시트로 이동합니다. "1. 파이썬 데이터 분석 기초" 아래의 I3 셀을 선택한 뒤 =py() 를 입력하여 Python 편집기를 실행합니다.
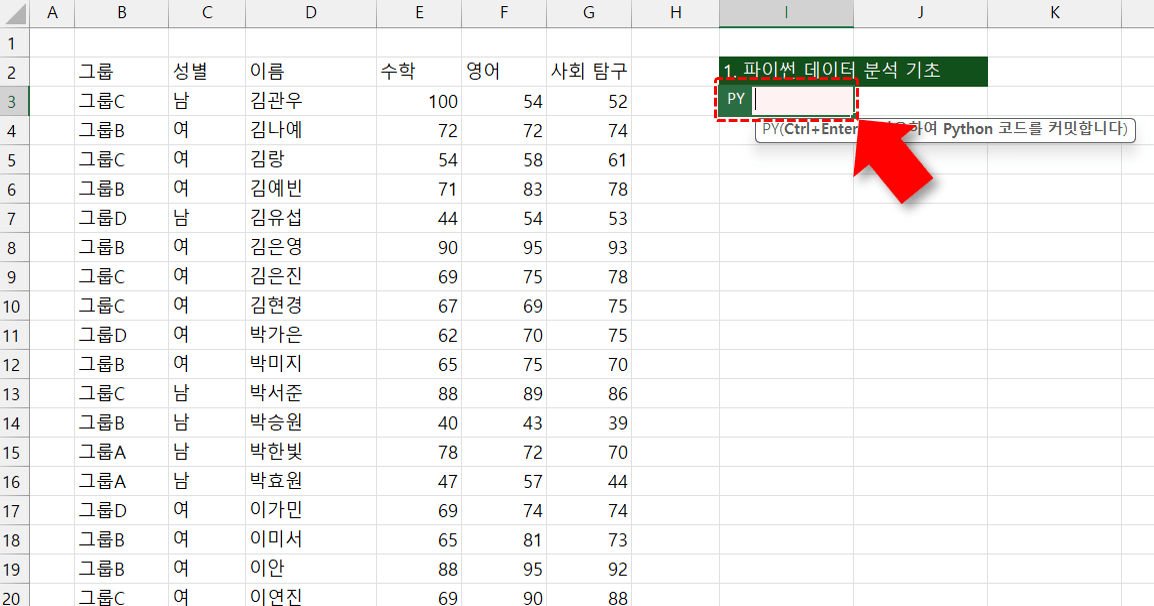
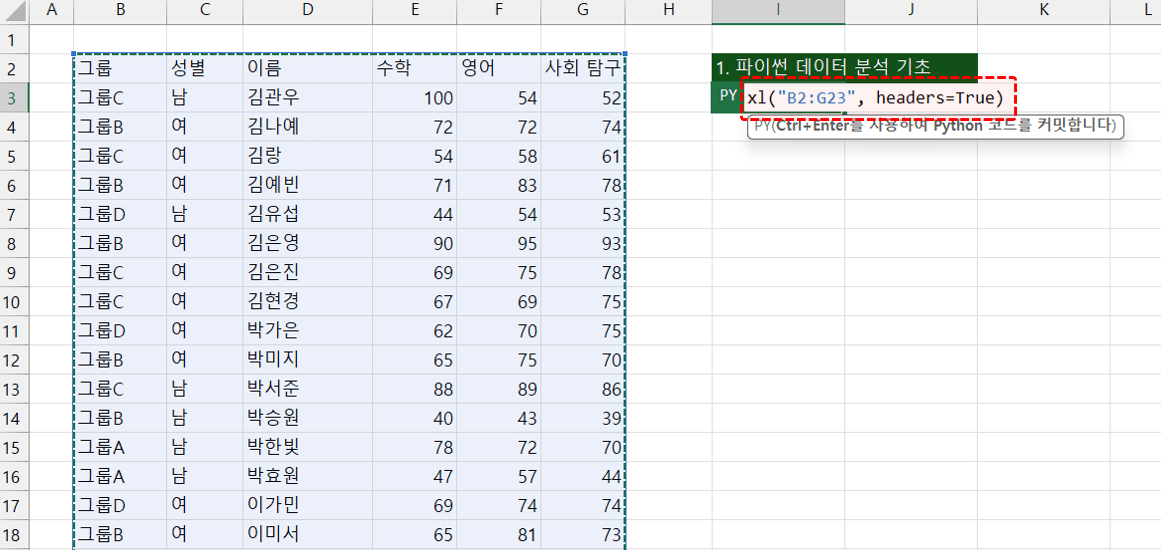
- Python 편집기에서 왼쪽에 데이터가 작성된 B2:G23 범위를 마우스로 드래그하면, 아래 그림과 같이 코드가 자동으로 작성됩니다.
xl("B2:G23", headers=True) #B2:G23 범위의 데이터를 DataFrame 개체로 생성
 오빠두Tip : xl 함수는 Python 편집기에서 사용되는 함수로, '범위·이름 범위·표·쿼리'를 참조할 수 있습니다.
오빠두Tip : xl 함수는 Python 편집기에서 사용되는 함수로, '범위·이름 범위·표·쿼리'를 참조할 수 있습니다. - Ctrl + Enter 로 Python 코드를 실행하면 셀 안에 'DataFrame' 개체가 생성됩니다. 개체 왼쪽에 표시된 마름모 모양의 아이콘을 클릭하면 개체 안에 작성된 데이터를 미리 볼 수 있습니다.
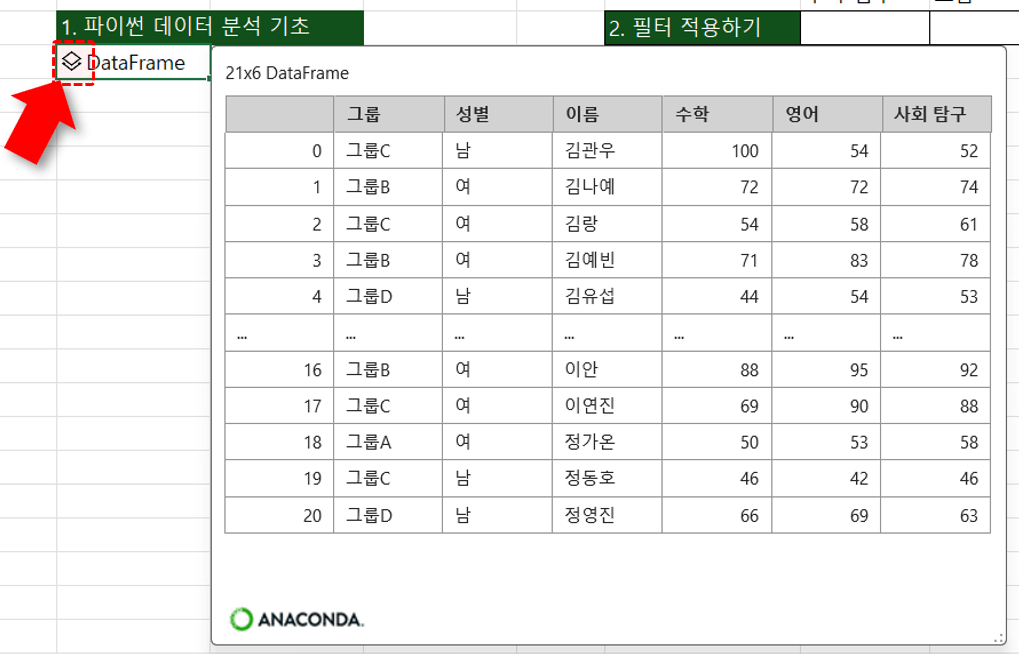 오빠두Tip : DataFrame은 파이썬 Pandas 라이브러리에서 사용하는 2차원 배열로, 엑셀의 이름 범위와 유사한 개념입니다. 다만 DataFrame을 효과적으로 활용하려면 기본적인 코딩 지식이 필요하며, 이에 대한 상세 내용은 추후 Python 특강에서 다룰 예정입니다.
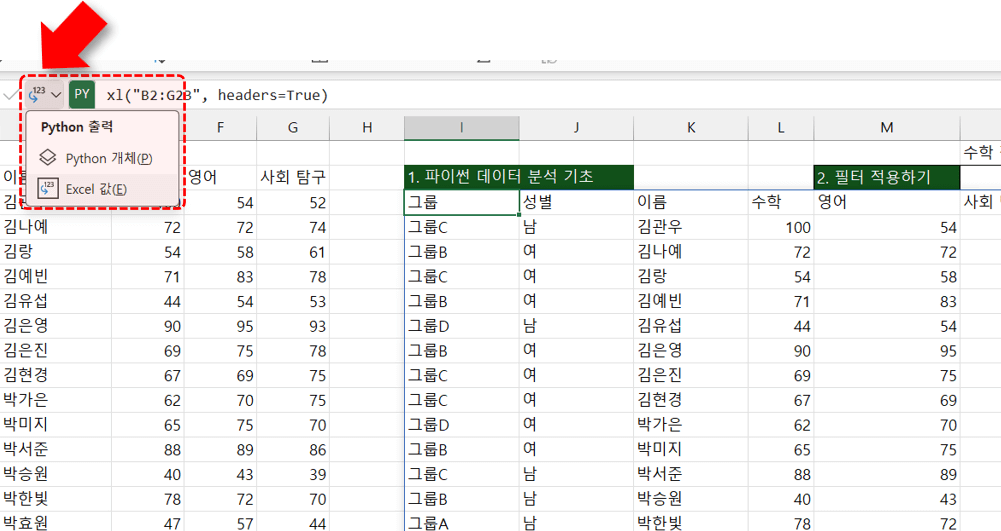
오빠두Tip : DataFrame은 파이썬 Pandas 라이브러리에서 사용하는 2차원 배열로, 엑셀의 이름 범위와 유사한 개념입니다. 다만 DataFrame을 효과적으로 활용하려면 기본적인 코딩 지식이 필요하며, 이에 대한 상세 내용은 추후 Python 특강에서 다룰 예정입니다. - Python 편집기 반환 형식 변경 : Python 편집기에서 반환되는 값은 'Python 개체' 또는 'Excel 값' 형태로 출력할 수 있습니다.
· Python 개체 : DataFrame, Image, Array 등의 개체로 출력합니다. 개체로 출력할 경우 Python 편집기에서 해당 셀을 바로 참조하여 활용할 수 있습니다.
· Excel 값 : 배열·이미지를 엑셀 시트 위에 바로 출력합니다. - 방금 Python 코드를 작성한 I3 셀을 선택한 뒤, 수식 입력줄 왼쪽의 마름모 모양 아이콘을 클릭하면 'Python 출력' 형식을 선택할 수 있습니다. 출력 방식으로 'Excel 값'을 선택하면 DataFrame의 데이터가 엑셀 범위로 출력됩니다.
- 또는 Python 코드를 작성한 셀을 선택한 뒤 단축키 Ctrl + Alt + Shift + M 을 동시에 누르면 파이썬 출력 방식을 빠르게 전환할 수 있습니다.

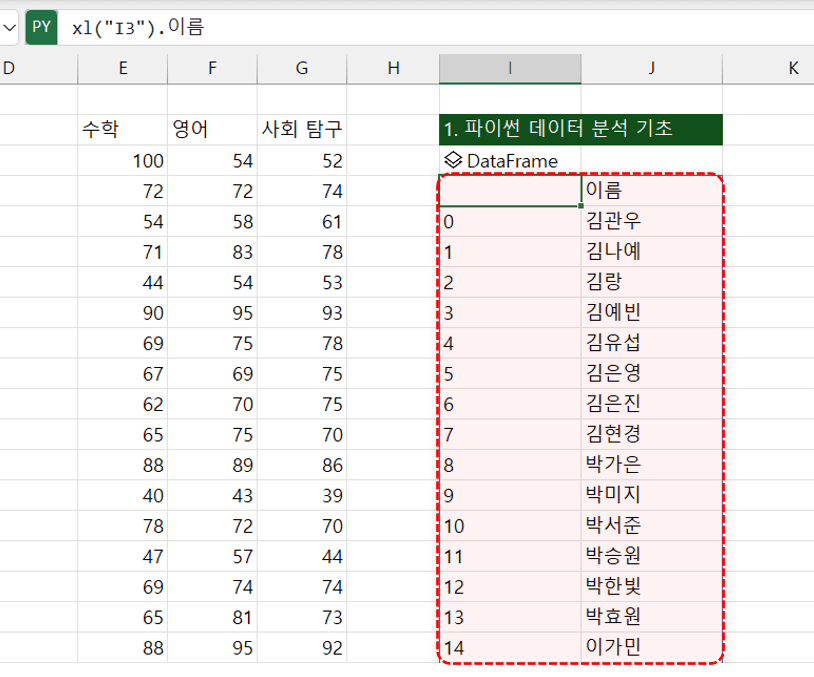
- DataFrame 특정 필드 선택 : 이번에는 DataFrame 아래쪽의 I4 셀을 선택한 뒤 Python 편집기를 실행하고, 아래와 같이 코드를 작성합니다. DataFrame 뒤에 마침표(.)를 찍고 머리글을 작성하면 DataFrame에서 특정 필드를 선택할 수 있습니다.
xl("I3").이름 #이름 필드 선택
- 작성한 Python 코드를 Ctrl + Enter로 실행하면 Series(1차원 배열)가 반환됩니다. 반환 형식을 Excel 값으로 변경하면 DataFrame에서 이름 필드만 선택된 결과를 확인할 수 있습니다.
- 다만 마침표(.)로 필드를 지정할 때 필드 이름에 공백이 포함되어 있으면 오류가 발생합니다. 따라서 공백이 들어간 필드를 참조할 때는 아래와 같이 대괄호를 사용하며, 이때 "마침표는 사용하지 않습니다."
xl("I3")["사회 탐구"] #공백이 들어간 필드 선택
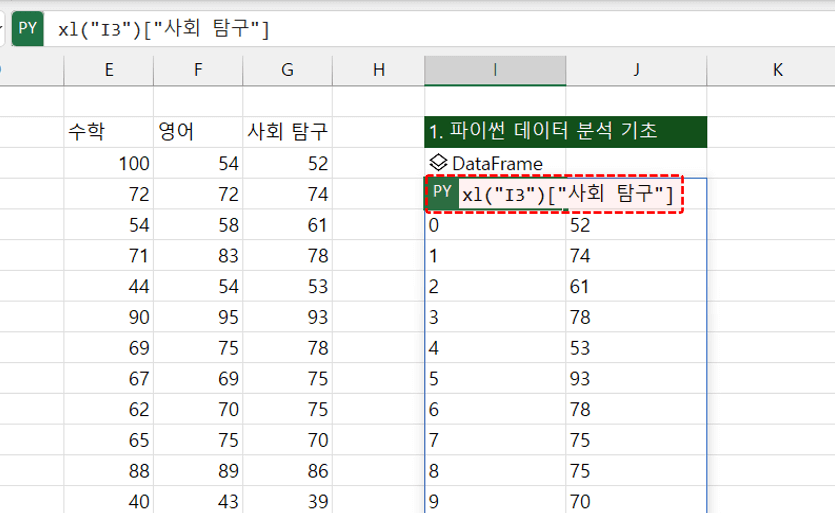 오빠두Tip : 대괄호 안에서 필드를 참조할 때에는 큰따옴표(") 또는 작은따옴표(')를 모두 사용할 수 있지만, 시작과 종료 기호는 반드시 일치해야 합니다.
오빠두Tip : 대괄호 안에서 필드를 참조할 때에는 큰따옴표(") 또는 작은따옴표(')를 모두 사용할 수 있지만, 시작과 종료 기호는 반드시 일치해야 합니다. - DataFrame 여러 필드 선택 : 대괄호를 사용하면 여러 필드를 동시에 선택할 수 있습니다. DataFrame에서 여러 필드를 선택할 때에는 아래와 같이 코드를 작성하며, 작성한 순서대로 필드가 선택됩니다.
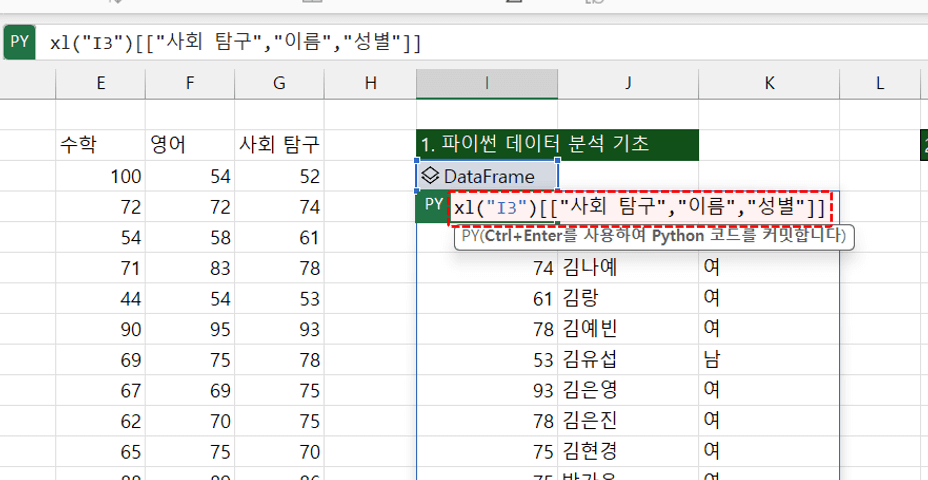
xl("I3")[["사회 탐구","이름","성별"]] #여러 필드 동시 선택
- 변수로 개체 참조하기 : Python 코드를 작성할 때 개체가 반환된 셀을 직접 참조할 수도 있지만, 변수를 사용하면 코드를 더욱 효율적으로 작성할 수 있습니다. I4 셀의 Python 코드를 제거한 뒤 I3 셀의 Python 코드를 아래와 같이 수정합니다. 아래 코드를 실행하면 B2:G23 범위의 데이터를 담은 DataFrame이 'test'라는 이름의 변수로 할당됩니다.
test = xl("B2:G23", headers=True) #DataFrame을 test라는 변수로 할당

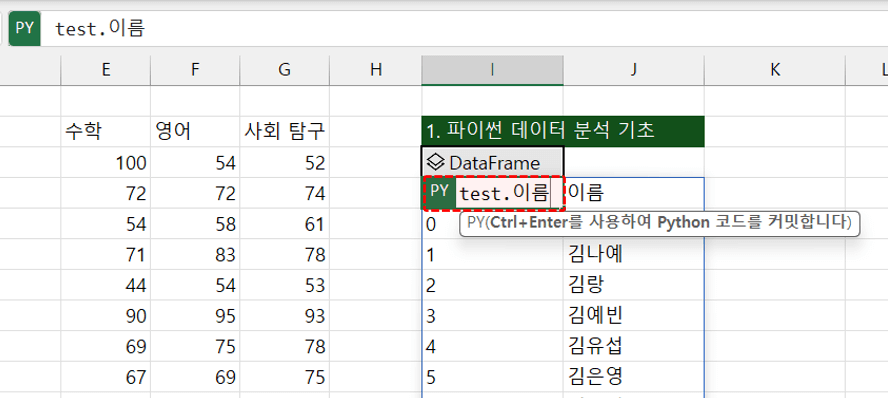
- 이제 I4 셀을 선택한 뒤 아래와 같이 코드를 작성하면 test 변수의 '이름' 필드가 선택됩니다.
test.이름 #test라는 변수의 '이름' 필드 선택
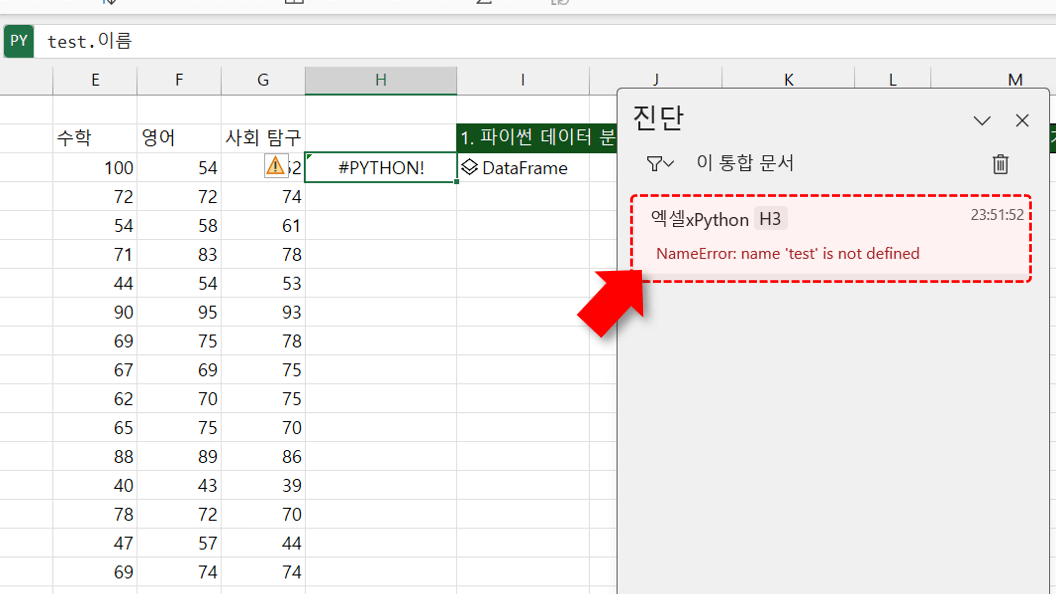
- 엑셀 Python의 계산 방향 : Python 코드를 여러 셀에 나누어 작성할 때에는 엑셀 Python의 계산 순서인 좌→우, 상→하를 고려해야 합니다. I4 셀에 작성한 코드를 잘라내어 H3 셀로 옮기면 아래 그림과 같이 "test라는 이름의 변수를 찾을 수 없습니다."라는 오류가 발생합니다. 이는 I3 셀에서 'test' 변수가 할당되기 이전에 H3 셀의 코드가 먼저 실행되기 때문입니다.
- 여기까지 엑셀 Python을 사용할 때 알아 두어야 할 기본기를 모두 살펴봤습니다. 지금부터는 본격적으로 다양한 예제와 함께 엑셀 Python 코드를 실습해 보겠습니다.
예제1. describe 함수 - 원클릭 기술통계
엑셀 Python을 활용하면 데이터의 기술통계를 함수 하나로 간편하게 구할 수 있습니다.
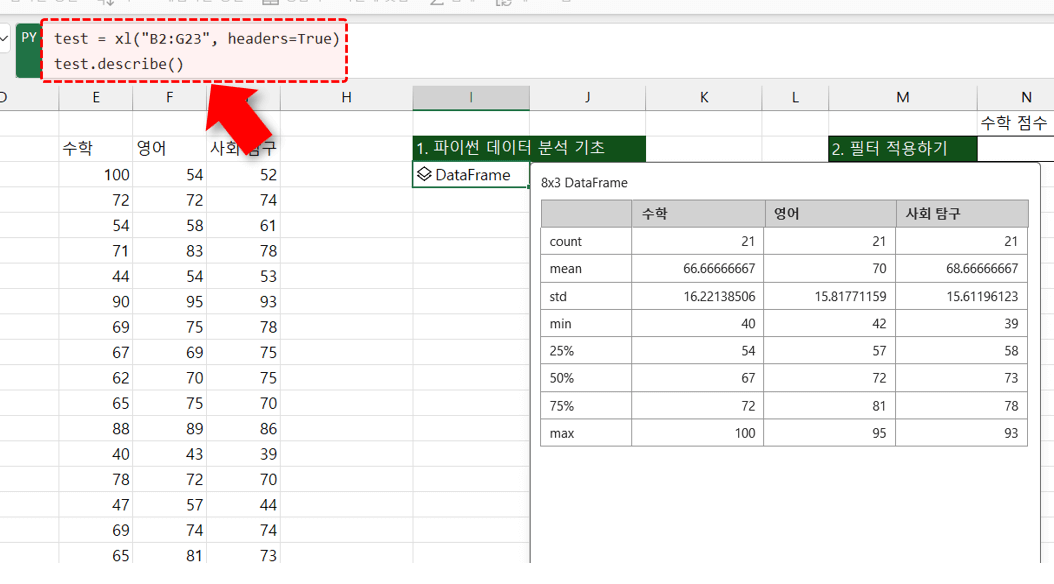
- 원클릭 기술통계 구하기 : 예제파일의 [엑셀xPython] 시트로 이동한 뒤 I3 셀에 아래 파이썬 코드를 작성하면, B2:G23 범위 데이터가 test라는 이름의 변수로 할당됩니다.
test = xl("B2:G23", headers=True) #B2:G23 범위의 데이터를 DataFrame 개체로 생성
- 이어서 아래 Python 코드를 작성한 뒤 실행하면 B2:G23 범위에 작성된 데이터의 기술통계 값을 얻을 수 있습니다.
test.describe() #test로 할당된 DataFrame의 기술통계 출력
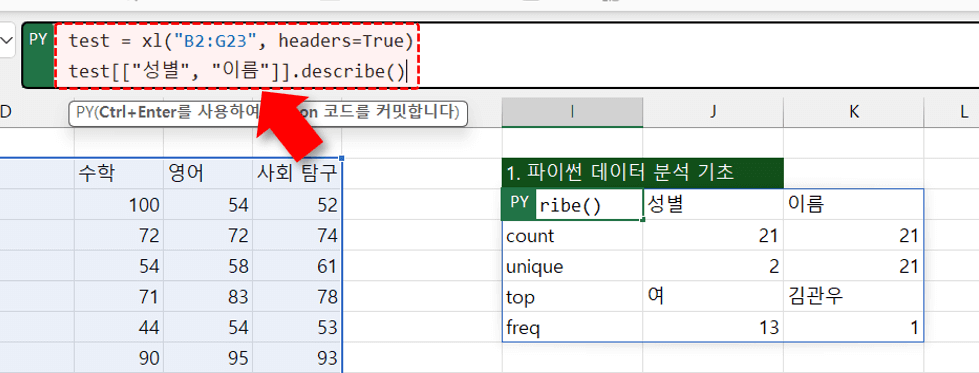
- describe 함수는 기본적으로 숫자 데이터를 집계합니다. 특정 필드의 기술통계만 구하거나 문자 데이터를 포함한 전체 기술통계 값을 구하려면 아래와 같이 코드를 작성합니다.
test[["이름", "성별"]].describe() #특정 필드의 기술통계를 구합니다. test.describe(include="all") #모든 필드의 기술통계를 구합니다.
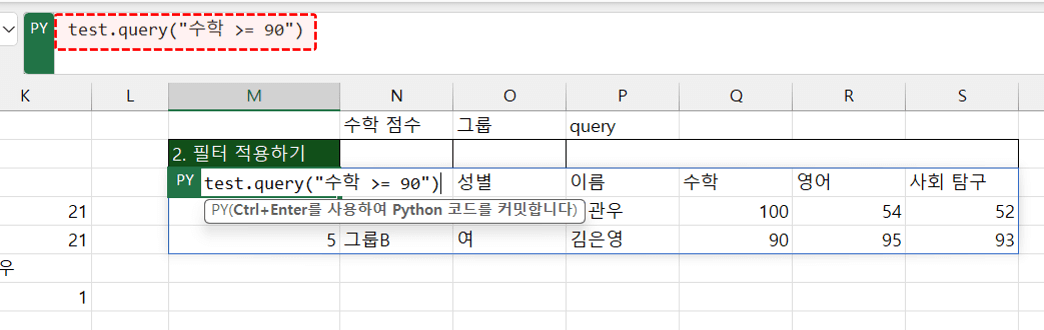
- query 함수로 필터 적용하기 : query 함수를 활용하면 여러 개의 복잡한 조건을 문장으로 작성하여 데이터를 손쉽게 필터링할 수 있습니다. 시트의 M3 셀에 아래와 같이 Python 코드를 작성한 뒤 실행하면, test 데이터에서 수학 점수가 90점 이상인 항목을 필터링합니다.
test.query("수학 >= 90") #test 데이터에서 수학점수가 90점 이상인 항목을 필터링
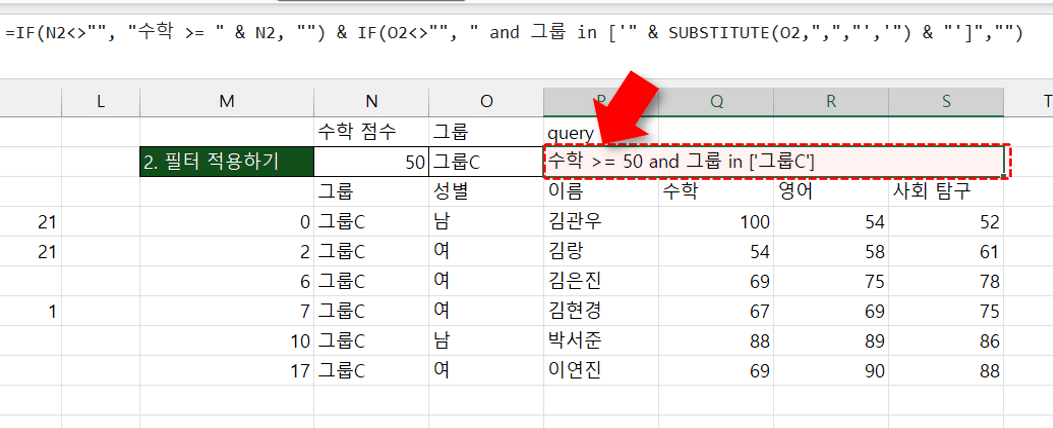
- 아래 그림과 같이 Python 코드의 조건을 엑셀 셀과 연동하면 실시간 필터링 분석 보고서를 만들 수 있습니다. Python 코드를 엑셀 셀과 연동하는 자세한 방법은 영상 강의를 참고하세요.
예제2. pivot_table/plot 함수 - 자동화 피벗테이블/차트 만들기
Python 함수를 활용하면 값이 바뀌었을 때 실시간으로 구조가 갱신되는 자동화 피벗테이블을 만들 수 있습니다.
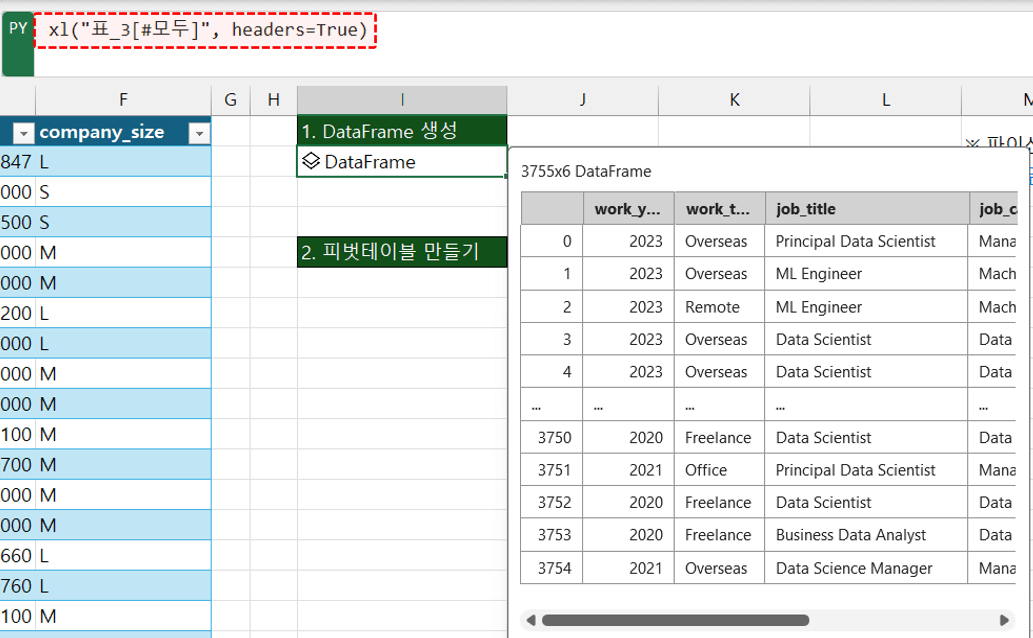
- DataFrame 만들기 : 예제파일에서 [피벗&차트분석] 시트로 이동합니다. I2 셀에 아래 Python 코드를 작성한 뒤 실행하여, 왼쪽 표에 작성된 직업별 연봉 표를 DataFrame 개체로 생성합니다.
xl("표_3[#모두]", headers=True) #표_3의 데이터를 DataFrame으로 생성
- 실시간으로 구조가 갱신되는 피벗테이블 : I6 셀을 선택한 뒤 아래 피벗테이블 코드를 실행하면, 연도별 급여 평균이 집계된 피벗테이블이 작성됩니다.
xl("I2").pivot_table(index="work_year",values="salary") #I2셀에 출력한 DataFrame 개체로 피벗테이블 만들기
 · index : 엑셀 피벗테이블에서 '행 영역'에 들어갈 필드입니다.
· index : 엑셀 피벗테이블에서 '행 영역'에 들어갈 필드입니다.
· values : 값 영역에 들어갈 필드입니다.
· columns : 열 영역에 들어갈 필드입니다.
· aggfunc : 값의 집계 방식을 지정합니다. 기본값은 'mean(평균)'입니다.
※ aggfunc 목록 : count(개수), nunique(고유개수), min(최소), max(최대), first/last(처음, 마지막), unique(고유값), std(표준편차), sum(합계), mean/median/mode(평균/중앙/최빈값), mad(평균절대편차)
※ pivot_table에 대한 자세한 설명은 pandas 공식 문서를 참고하세요. - 아래 그림과 같이 pivot_table 함수의 인수를 엑셀 셀과 연동하면, 값이 바뀌었을 때 행·열·집계 방식 등의 구조가 실시간으로 갱신되는 피벗테이블을 만들 수 있습니다.
pivot = xl("I2").pivot_table(index=xl("J5"),values="salary",aggfunc=xl("K5"),columns=xl("L5")) #index, value, aggfunc, columns 인수를 엑셀과 연동하여 구조가 실시간으로 바뀌는 피벗테이블 만들기
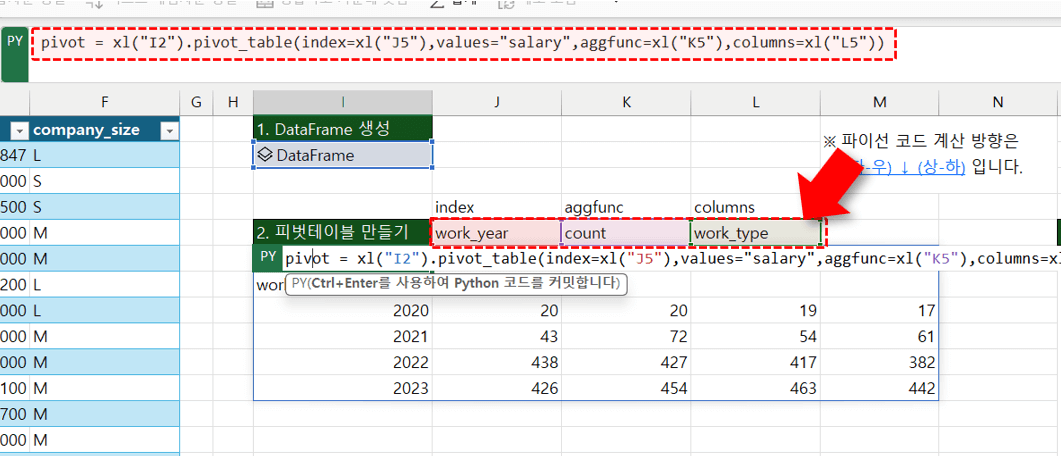
- 실시간으로 구조가 바뀌는 차트 : plot 함수를 사용하면 차트의 'x축 및 y축'은 물론 '차트 종류'까지 실시간으로 갱신되는 자동화 차트를 만들 수 있습니다. O6 셀에 아래 코드를 작성한 뒤 실행하면, I6 셀에 생성한 피벗테이블을 시각화한 차트가 만들어집니다.
pivot.plot() #pivot 이라는 데이터를 차트로 시각화하기
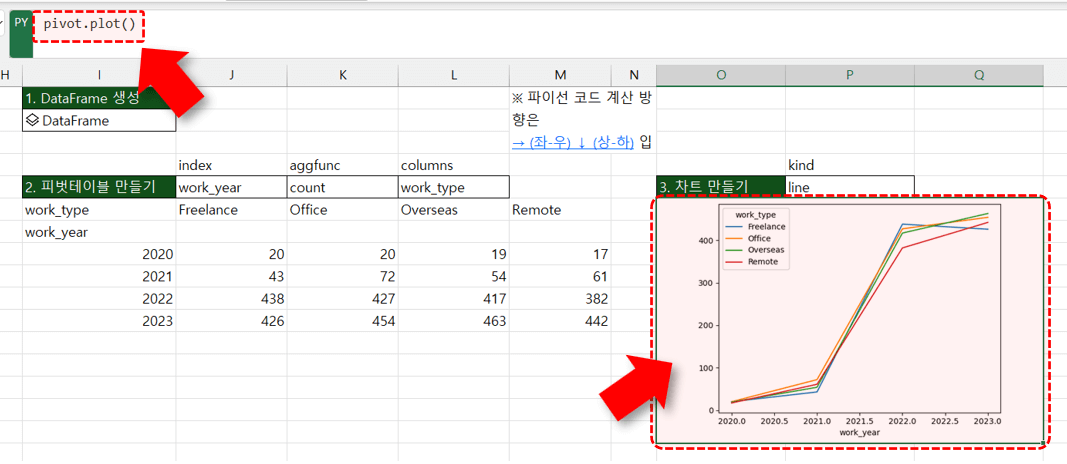
- plot 함수의 인수를 변경하면 x축·y축·차트 종류·차트 제목 등을 자유롭게 조정할 수 있습니다. O6 셀에 작성한 Python 코드를 아래와 같이 변경한 뒤, P5 셀의 목록에서 line, bar, barh를 선택하면 차트 종류가 실시간으로 변경됩니다.
pivot.plot(kind=xl("P5")) #P5셀에 선택한 차트 종류로 실시간 갱신하기
 · kind : 차트 종류 (line, bar, barh, hist, box 등)
· kind : 차트 종류 (line, bar, barh, hist, box 등)
· x, y : x축, y축에 사용할 데이터
· xlabel, ylabel : x축, y축에 표시할 축 레이블
· title : 차트 제목
· figsize : 차트 이미지 크기
※ plot에 대한 자세한 설명은 pandas 공식 문서를 참고하세요.
예제3. regex 라이브러리 - 비정제 데이터 가공하기
엑셀 Python에서 regex 라이브러리를 활용하면 정규표현식을 통해 불규칙한 데이터에서 정제된 데이터를 손쉽게 추출하고 가공할 수 있습니다.
- 불규칙한 댓글에서 날짜 데이터 추출 : 첫 번째 예제로 쇼핑몰의 제품 리뷰 중 "2023년 1월 1일", "2023-01-01", "2023/01/01", "23년1월1일" 등 불규칙하게 작성된 날짜 데이터만 추출하여 표준 날짜로 가공하는 regex 코드를 작성해 보겠습니다. 예제파일을 실행한 뒤 [날짜 추출] 시트로 이동합니다.
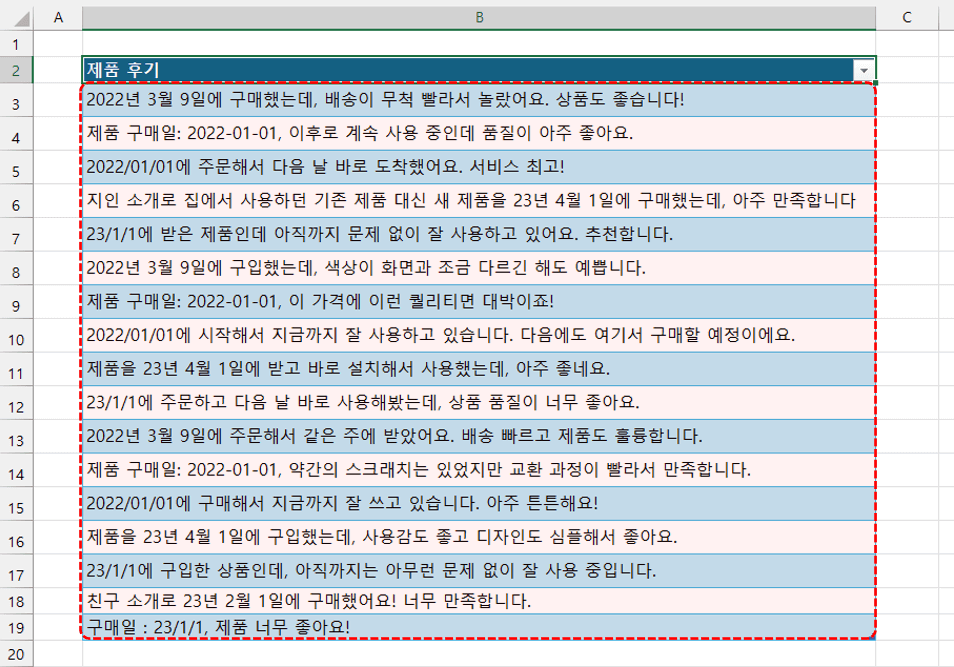
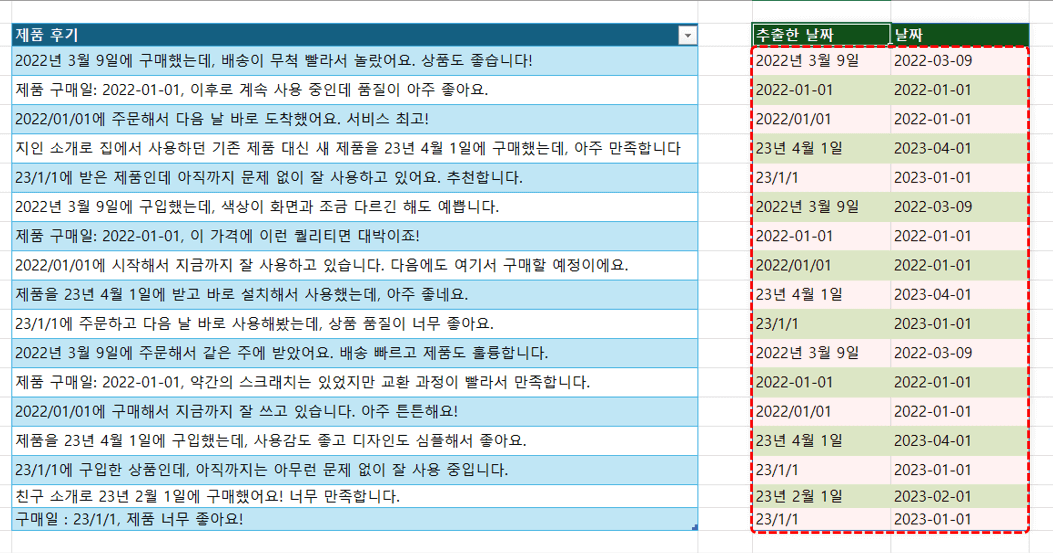
- D2 셀을 선택한 뒤 아래 Python 코드를 실행하면, 제품 후기에서 정제된 날짜 데이터가 깔끔하게 정리됩니다.
#Regex 패키지 추가 import re #제품 후기 DataFrame 불러오기 df = xl("표2[[#모두],[제품 후기]]", headers=True) #제품 후기에 Index 열 추가 df["index"] = df.index #추출한 날짜를 저장할 범위 생성 df_result = pd.DataFrame(index=df.index) df_result["추출한 날짜"] = None df_result["날짜"] = None #Regex 패턴 pattern = r'(?:(\d{2,4})년\s(0?[1-9]|1[0-2])월\s(0?[1-9]|[12][0-9]|3[01])일)|(?:(\d{4}|[0-9]{2})[\/-](0?[1-9]|1[0-2])[\/-](0?[1-9]|[12][0-9]|3[01]))' #제품 후기를 하나씩 돌아가면서 날짜 추출 for r in range(0, len(df)): matches = re.finditer(pattern, df.iat[r,0]) corrected_dates = [] for match in matches: original_date = match.group(0) date = match.groups() year, month, day = None, None, None #날짜가 년/월/일 패턴일 경우 if date[0]: year, month, day = date[0], date[1], date[2] #날짜가 yyyy-mm-dd 패턴일 경우 else: year, month, day = date[3], date[4], date[5] #년도가 2자리일 경우 앞에 20 추가 if len(year) == 2: year = "20" + year #출력 범위에 기존 날짜 및 수정한 날짜 추가 df_result.iat[r, 0] = original_date df_result.iat[r, 1] = f'{year}-{int(month):02d}-{int(day):02d}' #범위 출력 df_result
 오빠두Tip : 날짜 추출 시트에는 데이터가 입력되면 자동으로 머리글과 줄무늬 서식을 적용하는 조건부서식이 설정되어 있습니다. 조건부서식에 대한 자세한 설명은 아래 5분 기초 영상강의를 참고하세요.
오빠두Tip : 날짜 추출 시트에는 데이터가 입력되면 자동으로 머리글과 줄무늬 서식을 적용하는 조건부서식이 설정되어 있습니다. 조건부서식에 대한 자세한 설명은 아래 5분 기초 영상강의를 참고하세요.
- 불규칙한 주소 데이터 정제하기 : Regex를 사용하면 시/구/동, 시/군/면/읍 등으로 불규칙하게 작성된 주소 데이터를 시/구/동 단위로 정리할 수 있습니다. 예제파일에서 [주소 추출] 시트로 이동한 뒤, D2 셀에 아래 코드를 실행하면 주소 데이터가 시/구/동 단위로 깔끔하게 정리됩니다.
#Regex 패키지 추가 import re #주소 DataFrame 만들기 df = xl("표3[[#모두],[주소]]", headers=True) #Regex 패턴 pattern = "(?:(.+[도시]\s)(.+[시구군]\s)(.+?[읍면동])\s)" results = [] #각 항목을 하나씩 돌아가며 시/구/동 추출 for r in range(0, len(df)): match = re.search(pattern, df.iat[r,0]) if match: 도시, 시구군, 읍면동 = match.groups() results.append((도시, 시구군, 읍면동)) #df_result 출력 결과에 추출한 필드를 추가 df_result = pd.DataFrame(results, columns=["도시", "시구군", "읍면동"]) #출력 결과 마지막 행에 원본 주소 필드 추가 df_result.insert(3, '기존 주소', df[:len(results)]) #결과 출력 df_result
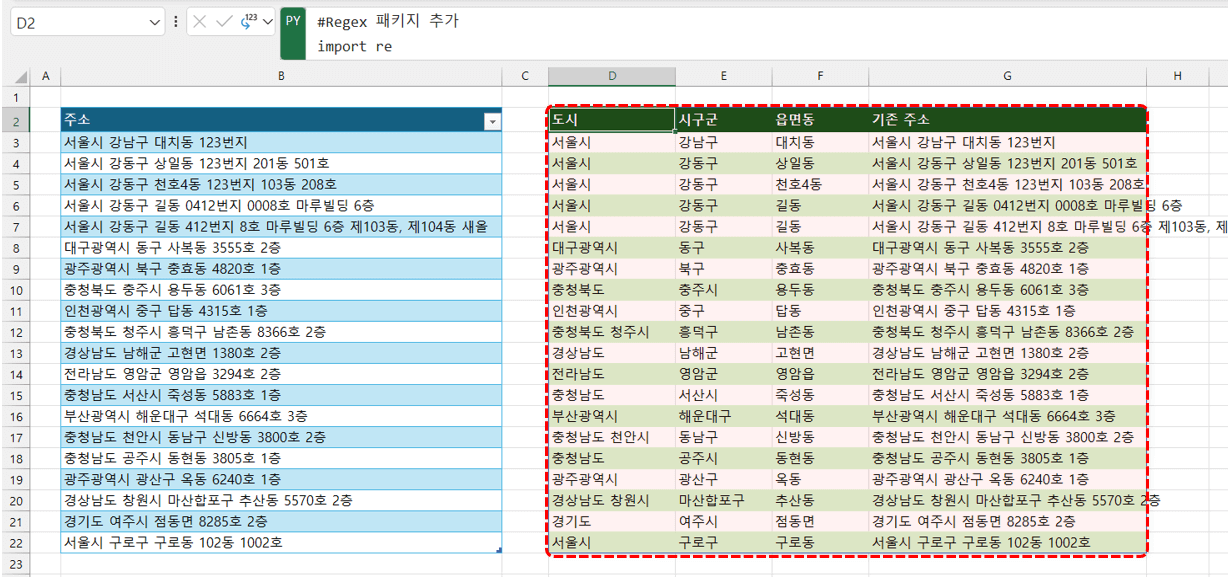
- 정규표현식을 쉽게 만드는 방법 : 정규표현식은 초보자에게 다소 복잡해 보일 수 있습니다. 정규표현식이 익숙하지 않다면 ChatGPT를 활용해 코드를 손쉽게 작성할 수 있습니다. 입력값과 원하는 결과값 샘플을 ChatGPT에 함께 제공하고 정규표현식을 활용한 Python 코드를 요청하면, 훌륭한 코드를 받을 수 있습니다. 다만 항상 완벽하게 동작한다는 보장은 없으므로 약간의 코딩 지식이 있으면 도움이 됩니다. 코딩 지식이 없더라도 걱정할 필요는 없습니다. 문제 상황과 해결 방향을 ChatGPT에 설명하면 친절한 안내와 함께 코드 작성을 도와줍니다.
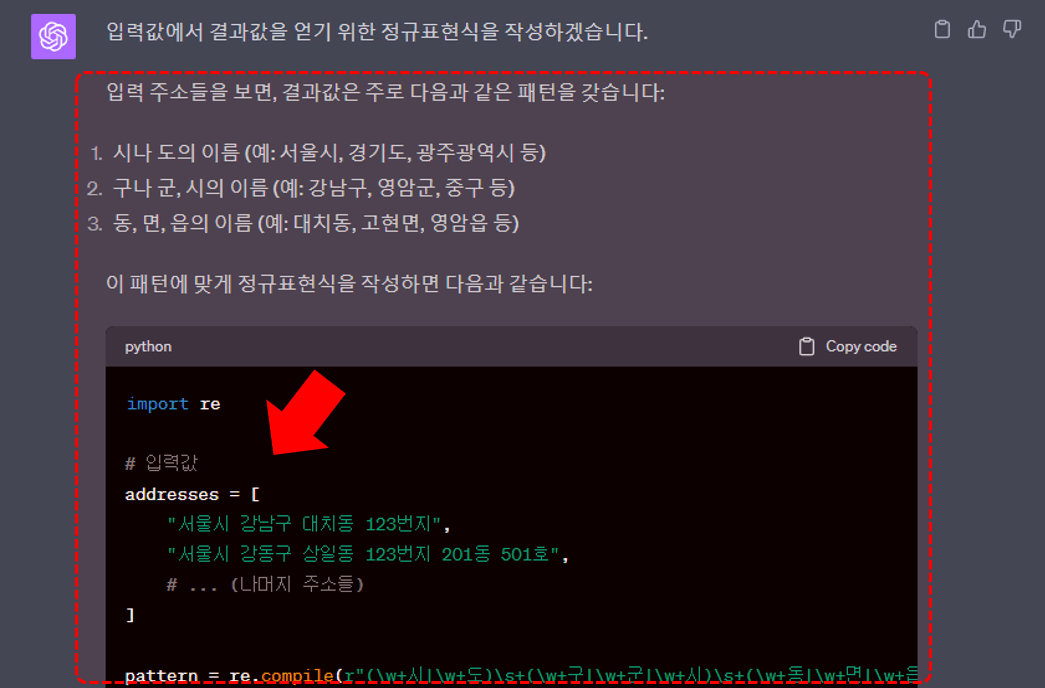
아래 입력값에서 결과값을 얻기 위한 정규표현식과 Python 코드를 작성해주세요.
입력값 :
서울시 강남구 대치동 123번지
서울시 강동구 상일동 123번지 201동 501호
등등.. 입력값 작성결과값 :
서울시 강남구 대치동
서울시 강동구 상일동
등등.. 원하는 결과값 형태 작성
예제4. 실시간 주식 분석 차트 만들기
엑셀 파워쿼리와 Python을 함께 활용하면 인터넷에서 실시간 주식 정보를 받아온 뒤 주식 트렌드를 분석하는 것도 가능합니다.
예제파일에서 [주식분석] 시트의 L2 셀에 아래 Python 코드를 작성한 뒤 실행하면, 선택한 주식의 최근 10일간 주식 트렌드를 분석하는 차트가 작성됩니다.
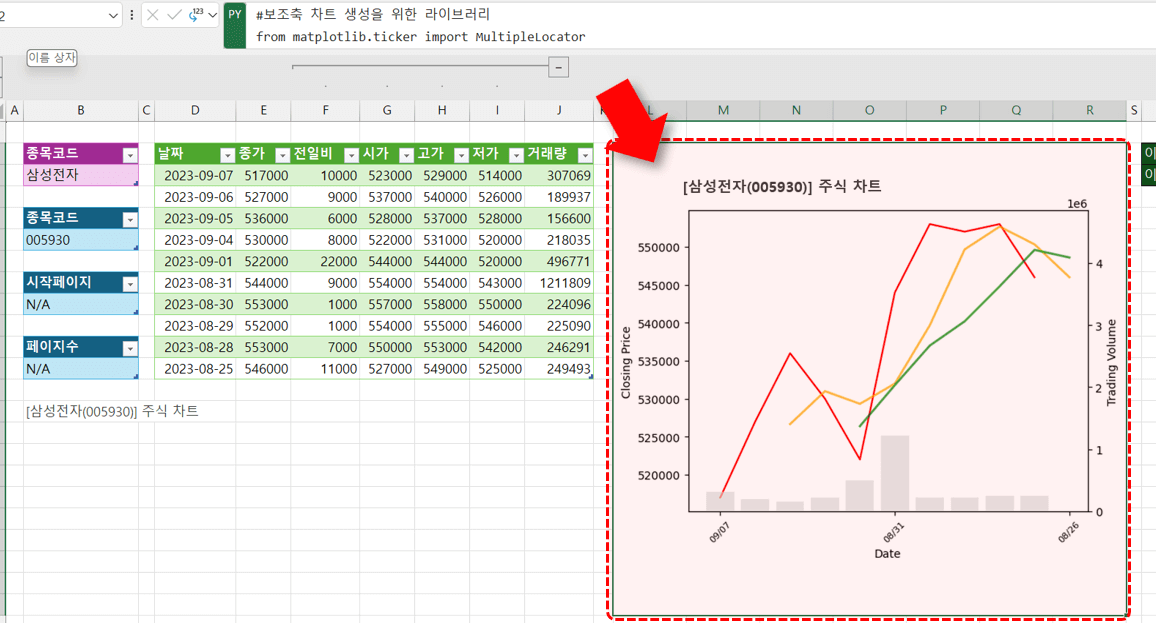
#보조축 차트 생성을 위한 라이브러리 from matplotlib.ticker import MultipleLocator #데이터프레임 인덱싱 df_stock = xl("일별시세[#모두]", headers=True) df_stock = df_stock[["날짜","종가","거래량"]] df_stock["날짜"] = pd.to_datetime(df_stock["날짜"]) indexed_df = df_stock.set_index(["날짜"]) #이동평균 예측 (단위 : 전체 기간 ÷ 10) forecast_cnt = int(len(indexed_df.index)/10) diff = indexed_df["종가"].iloc[-1] - indexed_df["종가"].iloc[-2] future_dates = [indexed_df.index[-1] + pd.DateOffset(days=i) for i in range(1, forecast_cnt+1)] future_values = [indexed_df["종가"].iloc[-1] + i*diff for i in range(1, forecast_cnt+1)] future_거래량 = [np.nan]*forecast_cnt df_future = pd.DataFrame({'종가': future_values, '거래량': future_거래량}, index=future_dates) #기존 데이터에 예측치 추가 df_combined = pd.concat([indexed_df, df_future]) #5일, 10일 이평선 추가 df_combined['5_day_MA'] = df_combined['종가'].rolling(window=xl("U2")).mean() df_combined['10_day_MA'] = df_combined['종가'].rolling(window=xl("U3")).mean() #차트 X축 표시용 텍스트 변환 df_combined.index = pd.to_datetime(df_combined.index).strftime('%m/%d') indexed_df.index = pd.to_datetime(indexed_df.index).strftime('%m/%d') df_future.index = pd.to_datetime(df_future.index).strftime('%m/%d') #차트 플롯 (주축) fig, ax1 = plt.subplots() x = df_combined.index x_actual = indexed_df.index x_forecast = df_future.index ax1.plot(x_actual, indexed_df["종가"], color="red", zorder=1, label='Actual') ax1.plot(x_forecast, df_future["종가"], color="blue", linestyle='--', zorder=2, label='Forecast') ax1.plot(df_combined.index, df_combined['5_day_MA'], color="orange", linestyle='-', zorder=3, label='5-day MA', lw=2, alpha=0.7) ax1.plot(df_combined.index, df_combined['10_day_MA'], color="green", linestyle='-', zorder=3, label='10-day MA', lw=2, alpha=0.7) #차트 플롯(보조축) ax2 = ax1.twinx() ax2_max = df_combined["거래량"].max() ax2.bar(x, df_combined["거래량"], color=(210/250,210/250,210/250), alpha=0.6, zorder=3) ax2.set_ylim(0,ax2_max*4) #차트 시각화 ax1.xaxis.set_major_locator(MultipleLocator(5)) for label in ax1.xaxis.get_ticklabels(): label.set_fontsize(8) label.set_rotation(45) #ax1.set_title("제목을 입력합니다.") ax1.set_xlabel("Date") ax1.set_ylabel("Closing Price") ax2.set_ylabel("Trading Volume") #차트 출력 plt.show(fig)
이제 B3 셀에서 원하는 주식 종목을 선택하면, 쿼리가 실행되면서 선택한 종목의 최근 10일 주식 정보와 함께 차트가 갱신됩니다.
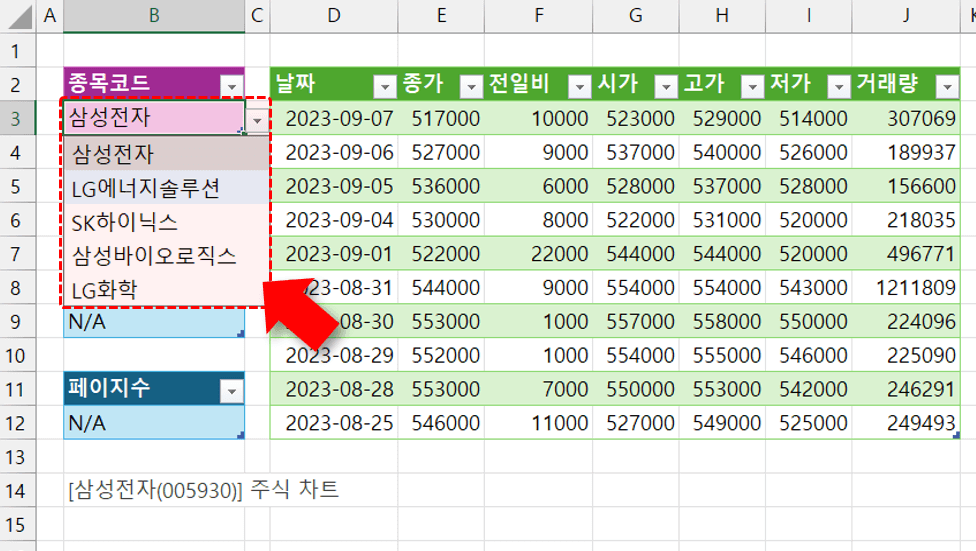

아직 초보단계라 어디에 더 활용할 수 있을것인지는 더 공부해봐야 알겠지만 이제 엑셀의 범용성이 크게 확장된 것 같네요
우선 F2를 눌러서 셀 편집 단축키가 잘 동작하는지 우선 확인해보시길 바랍니다.
만약 F2 단축키가 잘 동작한다면, Ctrl + F2가 동작하지 않는 이유는 Fn키(펑션키) 설정 또는 외부 프로그램에서 Ctrl + F2를 우선 사용중이어서 그럴 수 있으니 한번 확인해보세요.
감사합니다
py. xl("B2:G23", headers=True) 후 실행하면, "값 오류" 표시가 뜹니다.
왜 그럴까요?
파이썬 함수는 파이썬 편집기 안에서 작성하셔야 합니다.
영상 강의와 게시글을 참고하여 다시 입력해보세요.
감사합니다.