

엑셀 통계분석의 시작, 대표값 분석의 모든 것 - 핵심정리
통계분석의 가장 근본이 되는 기술적 통계에서 사용되는 대표값 - 핵심지표 4가지의 계산법 및 해석원리 살펴보기
이 강의에서는 엑셀의 STDEV.S·SKEW·KURT 함수로 표준편차와 왜도, 첨도를 계산하고, 산출된 통계지표를 바탕으로 데이터 분포를 해석하는 방법을 다룹니다. 평균·중앙값·최빈값 같은 대표값과 함께 살펴보며, 표본 데이터의 정규분포 여부를 판단하고 평균 ± 2 × 표준편차 범위 안에 95%의 데이터가 포함되는지 확인하는 실전 분석 절차까지 정리합니다.

실습자료를 준비했어요
수업에서 사용한 예제 파일과 보충 자료를 한 곳에 정리했습니다!👇






대표값 / 주요 통계지표 3가지
실무 통계분석은 "주어진 데이터의 대표값과 통계지표를 올바르게 이해하는 것"에서 시작합니다. 현업에서 가장 자주 활용되는 대표값은 다음 세 가지입니다.
- 데이터 목록
1 2 2 3 4 5 25 - 주요 대표값 3가지
종류 값 설명 평균값(AVERAGE) 6 주어진 데이터 집단의 산술평균(전체 합계 ÷ 개수)을 의미합니다. 중앙값(MEDIAN) 3 데이터를 크기 순서대로 나열했을 때 정중앙에 위치하는 값입니다. 데이터 개수가 짝수일 경우에는 중앙에 위치한 두 값의 평균으로 계산합니다. 최빈값(MODE) 2 데이터 집단에서 가장 자주 등장한 값을 의미합니다.
대표값과 더불어 실무 통계분석에서 유용하게 활용되는 통계지표 3가지가 있습니다. 바로 '표준편차'와 '왜도', 그리고 '첨도'입니다. 그 중에서도 표준편차는 데이터가 정규분포를 따른다는 전제 하에 다양한 통계분석에서 핵심 지표로 사용되므로 반드시 숙지해 두는 것이 좋습니다.
- 주요 통계지표 3가지
통계지표 설명 표준편차(STDEV) 데이터 분포가 평균으로부터 얼마나 떨어져 있는지 나타내는 지표입니다. 데이터 집단이 정규분포를 따를 경우, 평균으로부터 2 × 표준편차 떨어진 범위 안에 전체 데이터의 약 95%가 포함됩니다. 왜도(SKEW) 데이터 분포가 좌우로 얼마나 기울어져 있는지를 나타내는 지표입니다. 양수일 경우 분포가 왼쪽으로, 음수일 경우 오른쪽으로 치우쳐 있음을 의미합니다. 일반적으로 값이 -2 ~ 2 사이일 때 정규분포에 가깝다고 판단합니다. 첨도(KURT) 데이터 분포가 얼마나 뾰족한 형태를 이루는지 나타내는 지표입니다. 값이 클수록 분포가 더욱 뾰족해집니다. 일반적으로 값이 8보다 작을 때 정규분포에 가깝다고 판단합니다.
표준편차는 값(변량)이 흩어져 있는 정도를 나타내는 통계지표입니다. 즉, 표준편차가 클수록 값들이 평균에서 멀리 떨어져 있거나 들쭉날쭉하게 분포한다는 의미입니다.
표준편차를 구하는 절차는 아래와 같습니다. 예시로, 다섯 명 학생의 시험 성적에 대한 표준편차를 단계별로 계산해 보겠습니다.
| 항목 | 학생1 | 학생2 | 학생3 | 학생4 | 학생5 |
| 값(변량) | 77 | 79 | 81 | 83 | 85 |
| 평균 | (77+79+81+83+85) ÷ 5 = 81 | ||||
| 편차 (변량-평균) |
77-81 = -4 | 79-81 = -2 | 81-81 = 0 | 83-81 = 2 | 85-81 = 4 |
| 편차제곱 | 16 | 4 | 0 | 4 | 16 |
| 분산 (편차제곱의 평균) |
(16+4+0+4+16) ÷ 5 = 8 | ||||
| 표준편차 | √8 = 2.828427... | ||||
표준편차는 엑셀의 STDEV 함수로 손쉽게 계산할 수 있습니다. 엑셀에서 STDEV를 입력하면 STDEV.P 함수와 STDEV.S 함수가 함께 표시되는데, P는 Population(모집단)의 약자, S는 Sample(표본집단)의 약자입니다.

실무에서는 대부분 표본 집단(샘플링 데이터)을 다루기 때문에, 특별한 상황이 아니라면 STDEV.S 함수를 사용하는 것이 일반적입니다.
표준편차는 실무에서 어떻게 활용되나요?
현업에서 다루는 대부분의 데이터는 전체 집단의 일부만 샘플링하여 분석합니다. 이렇게 분석된 결과를 토대로 모집단 전체를 설명할 수 있는 결론을 도출하게 되는데요.
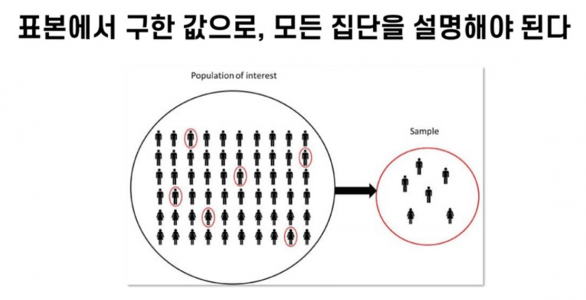
이때 표본이 모집단 전체를 대표할 수 있다는 가설을 세우기 위해, 데이터 집단이 '정규분포를 따른다'는 가정 하에 분석을 진행합니다. 그리고 데이터 집단이 정규분포를 따를 경우, 전체 데이터의 약 95%가 평균으로부터 2 × 표준편차 범위 안에 포함됩니다.
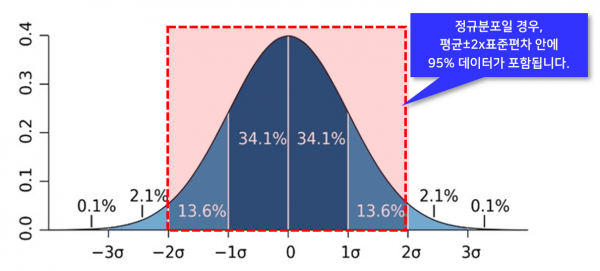
따라서 실무에서 표준편차는 '데이터가 정규분포를 따를 경우, 95%에 해당하는 대부분의 데이터는 평균 ± 2 × 표준편차 안에 포함된다'고 해석하는 용도로 자주 사용됩니다.
실전 데이터 분포 예측하기
표준편차를 통해 대부분의 데이터가 포함되는 범위인 '평균 ± 2 × 표준편차'를 설명하려면, 해당 데이터 집단이 반드시 정규분포를 따라야 합니다.
하지만 실무에서 다루는 데이터 중 일부는 정규분포에 가까운 모습을 보이지만, 완벽한 정규분포를 갖는 데이터는 거의 없습니다. 그래서 보통은 '왜도'와 '첨도'를 활용해 데이터의 정규분포 여부를 대략적으로 판단합니다. 실무에서 왜도와 첨도로 정규분포를 판단하는 기준은 아래와 같습니다.
-2 < 왜도 < 2
-3 < 첨도 < 8
일 경우, 정규분포를 따른다고 해석합니다.
이제 실전 예제를 통해 데이터 집단의 통계지표를 직접 구해 보고, 산출된 통계지표를 바탕으로 데이터 분포를 예측해 보겠습니다.
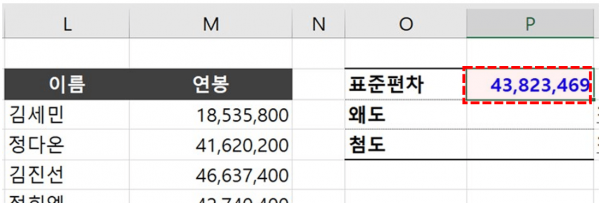
- 통계지표 구하기 : 예제파일을 실행한 뒤 [데이터 안정성] 시트로 이동합니다. 이후 P2셀에 아래 수식을 입력하여 데이터 집단의 표준편차를 구합니다. STDEV.S 함수에 대한 자세한 설명은 아래 관련 포스트를 참고하세요.
=STDEV.S(M3:M4736)
 오빠두Tip : 엑셀 STDEV.S 함수 상세설명 및 주의사항 바로가기
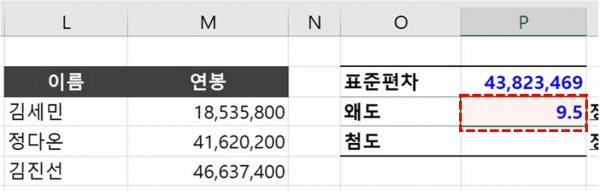
오빠두Tip : 엑셀 STDEV.S 함수 상세설명 및 주의사항 바로가기 - P3셀에 아래 수식을 입력하면 왜도가 계산됩니다. SKEW 함수에 대한 자세한 설명은 아래 관련 포스트를 참고하세요.
=SKEW(M3:M4736)
 오빠두Tip : 엑셀 SKEW 함수 상세설명 및 주의사항 바로가기
오빠두Tip : 엑셀 SKEW 함수 상세설명 및 주의사항 바로가기 - P4셀에 아래 수식을 입력하면 첨도가 계산됩니다. KURT 함수에 대한 자세한 설명은 아래 관련 포스트를 참고하세요.
=KURT(M3:M4736)
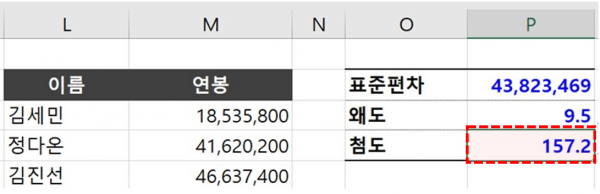 오빠두Tip : 엑셀 KURT 함수 상세설명 및 주의사항 바로가기
오빠두Tip : 엑셀 KURT 함수 상세설명 및 주의사항 바로가기 - 각각의 표준편차와 왜도, 첨도를 계산했습니다. 왜도와 첨도가 모두 큰 값을 나타내고 있으므로, 데이터 분포는 '왼쪽으로 치우친 뾰족한 형태'를 가질 것이라고 예측할 수 있습니다.
- 히스토그램 만들기 : 예제파일의 I2:J38 범위에 히스토그램을 만들기 위한 도수분포표를 미리 작성해 두었습니다. 히스토그램을 빠르게 만드는 방법은 별도 강의로 준비해 드릴 예정입니다. 예제파일의 I2:J38 범위를 선택한 뒤 [삽입] - [추천 차트]로 이동하여 세로막대형 차트를 삽입합니다.
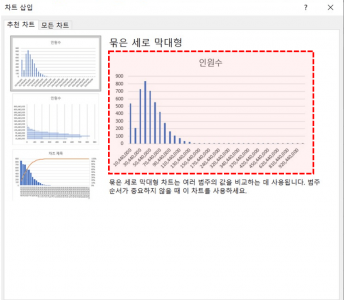
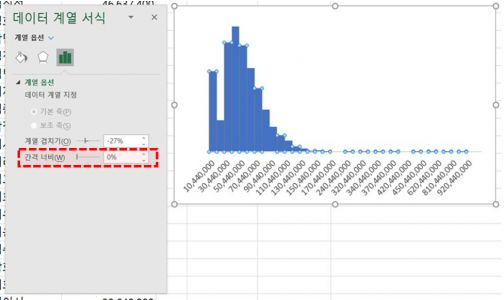
- 차트의 제목과 눈금선을 삭제한 뒤, 막대를 우클릭하여 [데이터 계열 서식]으로 이동합니다. 이후 간격 너비를 0%로 변경하면 히스토그램이 완성됩니다. 통계지표로 분석한 결과와 동일하게, 데이터가 왼쪽으로 치우친 뾰족한 형태로 분포하고 있음을 확인할 수 있습니다.
왜도랑 첨도는 전혀 몰랐던 내용인데 잘 배우고 갑니다
아니면 평균을 맞추는 작업을 하고 나서 표준편차를 비교하는 그런 작업을 해야할까요?
A그룹 샘플들이 평균으로부터 가장 멀리 떨어져있다?!
A. 평균 40 표준편차 10
B 평균 50 표준편차 8
c 평균 60 표준편차 5
다만, 개체수가 적다면 이상치로 인해 결과값이 왜곡될 수도 있으므로 참고하시면 좋겠습니다.