



엑셀 파이썬, 코파일럿 고급 데이터 분석 | 최신 업데이트 완벽 정리!
엑셀 코파일럿 고급 분석 목차 바로가기
영상 강의
예제파일 다운로드
오빠두엑셀의 강의 예제파일은 여러분을 위해 자유롭게 제공하고 있습니다.
- [엑셀고급] 엑셀 코파일럿 파이썬 고급 데이터 분석 기초 맛보기예제파일
라이브 강의 전체영상도 함께 확인해보세요!
위캔두 회원이 되시면 매주 오빠두엑셀에서 진행하는 라이브강의 풀영상을 확인하실 수 있습니다.
코파일럿 고급 데이터 분석 / 파이썬 지원 버전 안내
드디어, 한국에서도 엑셀 코파일럿의 파이썬 고급 데이터 분석(Copilot with Python, Advanced Analysis) 기능이 정식으로 추가(25년 3월 26일) 되었습니다! 이제 기존에 엑셀만으로는 해결이 어려웠던 복잡한 데이터 분석도 코파일럿의 도움을 받아 손쉽게 해결할 수 있게 되었는데요.
이 기능은 아직 영어로만 요청 가능(추후 한국어 기능 지원 예정)하지만, 구글 번역기를 통해 간단히 번역해서 입력하면 됩니다. 먼저 이번에 새롭게 추가된 코파일럿 고급 데이터 분석과 파이썬을 사용하기 위한 버전을 알아보겠습니다.
✨ 엑셀 파이썬 (Python in Excel)
· 개인용 M365 (현재 채널) : 2407(17830.20128) 이상
· 비즈니스 M365 (월간 채널) : 2408(17928.20114) 이상
· Mac M365 : 16.95(25021921) 이상
· 웹 엑셀 : 비즈니스 사용자에게만 제공✨ 코파일럿 고급 데이터 분석 (Copilot with Python)
· 개인용 M365 (현재 채널) : 2409 (18025.00000) 이상
· 비즈니스 M365 (월간 채널) : 2410(18227.00000) 이상
· Mac M365 : 16.95(25021921) 이상
· 웹 엑셀 : 비즈니스 사용자에게만 제공현재 사용 중인 엑셀 버전은 [파일] 탭 - [계정] 에서 확인할 수 있습니다.
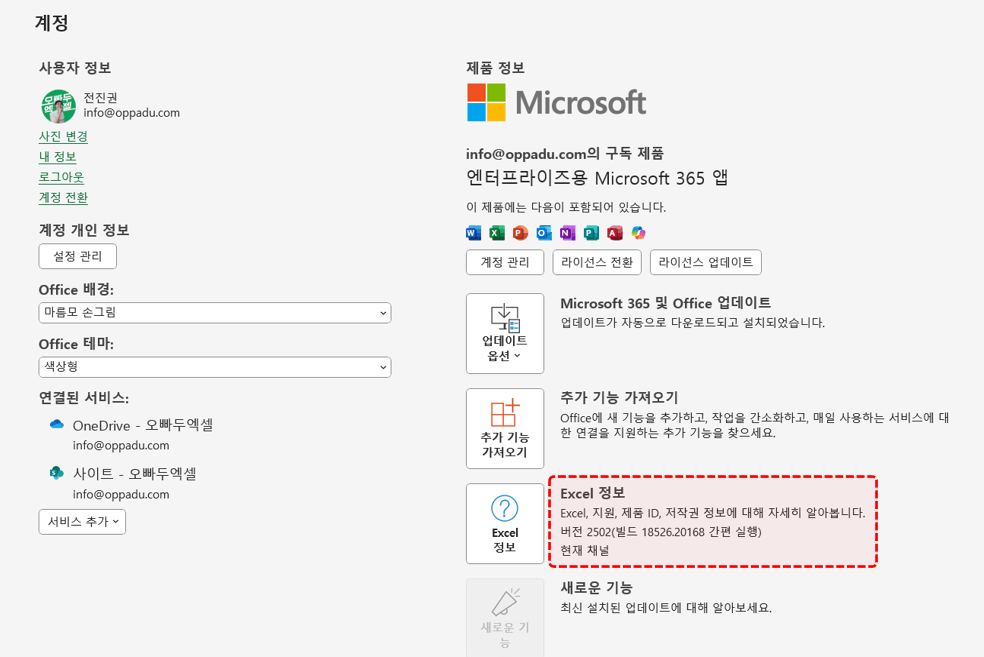
[파일] 탭 - [계정] 에서 엑셀 버전을 확인할 수 있습니다. 엑셀 파이썬 기본 제공 라이브러리
엑셀 파이썬은 일반적인 업무 자동화나 게임 개발이 아닌 "데이터 분석"에 특화되어 있으며, 아나콘다 데이터 분석 라이브러리를 기본으로 제공합니다. 또한 엑셀 파이썬은 ① 모든 작업을 클라우드에서 실행하므로 컴퓨터 사양과 무관하게 사용할 수 있고, 반드시 ② 인터넷이 연결된 상황에서만 사용할 수 있습니다.

엑셀 파이썬은 클라우드에서 동작하므로 인터넷이 연결된 환경에서만 사용할 수 있습니다. 엑셀 파이썬에서 기본으로 로딩되는 라이브러리는 아래와 같으며, 아래 목록은 [수식] 탭 - [파이썬] - [초기화] 버튼을 클릭해서 확인할 수 있습니다.
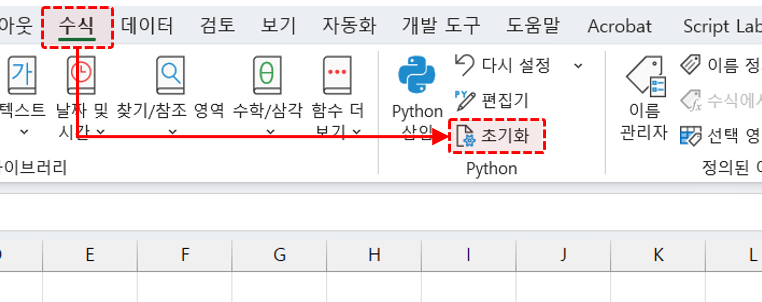
[수식] - 파이썬의 [초기화] 버튼을 클릭해서 기본으로 로딩되는 패키지를 확인합니다. # The following import statements are pre-loaded. import numpy as np import pandas as pd import matplotlib.pyplot as plt import statsmodels as sm import seaborn as sns import excel import warnings warnings.simplefilter('ignore') # Set default conversions for the xl() function. excel.set_xl_scalar_conversion(excel.convert_to_scalar) excel.set_xl_array_conversion(excel.convert_to_dataframe)
기본 라이브러리를 확인할 수 있습니다. 엑셀 파이썬에서 유용하게 사용할 수 있는 추천 라이브러리 목록은 다음과 같습니다.
✨ 기본 제공 라이브러리
· NumPy : 대량의 숫자 계산을 빠르게 처리
· pandas : 파이썬 안에서 엑셀과 비슷한 데이터 처리 작업이 필요할 때 사용
· Matplotlib : 보고서 시각화용. 커스터마이징 좋고 거의 모든 차트 시각화 가능.
· seaborn : 맷플롯립보다 예쁨, 커스터마이징 다소 제한, 통계 시각화 강점.
· statsmodels : 통계 분석 도구, 회귀분석, 시계열분석 등등..✨ 엑셀 파이썬 추천 라이브러리
· scikit-learn : 머신러닝 자동화 분석 (고객 분류, 이탈 예측 등)
· imbalanced-learn : AI 모델 학습 시 데이터가 불균형할 때
· wordcloud : 설문 결과 텍스트 시각화, 자주 언급된 키워드 분석
· TheFuzz : 고객명, 제품명 등의 비슷한 항목 자동 정리
· NLTK : 감성 분석, 문장 분석 (ex. 고객 불만 유형 분류 등), KONLPy는 아직 미제공
· qrcode : 웹 링크/명함용 QR코드 자동 생성인사이트 분석으로 데이터 빠르게 검토하기
실무에서 방대한 데이터를 처음 접할 대, 그 안에서 인사이트를 찾고 데이터를 분석하려면 상당한 시간이 필요할 수 있습니다. 그럴 때, 코파일럿의 데이터 인사이트 분석 기능을 사용하면 버튼 클릭 한 번으로 데이터의 인사이트를 빠르게 확인할 수 있습니다.
- 먼저 PC에서 코파일럿을 사용하려면 '자동 저장' 옵션을 켜야 합니다. 실습 파일을 실행한 후, 엑셀 화면 좌측 상단의 [자동 저장] 버튼을 클릭해서 원드라이브에 파일을 저장합니다. 저장한 파일은 원드라이브의 최상단 경로에 자동으로 저장됩니다.

- 파일을 저장하면 아래 그림과 같이 자동 저장을 켤 수 있습니다.
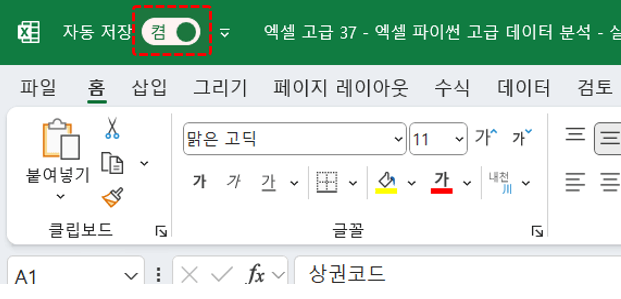
코파일럿을 사용하기 위해 자동 저장을 켭니다. - 예제파일에서 [인사이트 분석] 시트로 이동한 후, 표를 선택하고 [홈] 탭 - [Copilot] 을 클릭해서 코파일럿을 실행합니다.
홈 탭에서 코파일럿을 실행합니다. - 코파일럿의 제안 목록 중, 가장 첫번째 항목인 [데이터 인사이트를 표시해 주세요]를 클릭하면 데이터 인사이트 분석이 시작됩니다.

[데이터 인사이트를 표시해주세요] 버튼을 클릭해서 인사이트 분석을 실행합니다. - 잠시만 기다리면 데이터 인사이트 분석이 완료되며, [그리드에 모든 인사이트를 추가하세요] 버튼을 클릭해서 인사이트 분석 결과 시트를 생성합니다.
그리드에 모든 인사이트를 추가합니다. - 이번에 분석할 인사이트는 '각 등급별 소득 및 지출 현황' 입니다. 따라서, 각 등급별 표본 수가 다르므로 피벗테이블의 집계 방식을 합계에서 평균으로 변경해야 합니다. 새로 추가된 시트 아래쪽 피벗테이블에서 값을 우클릭 - [값 요약 기준] 에서 집계 방식을 평균으로 변경합니다.
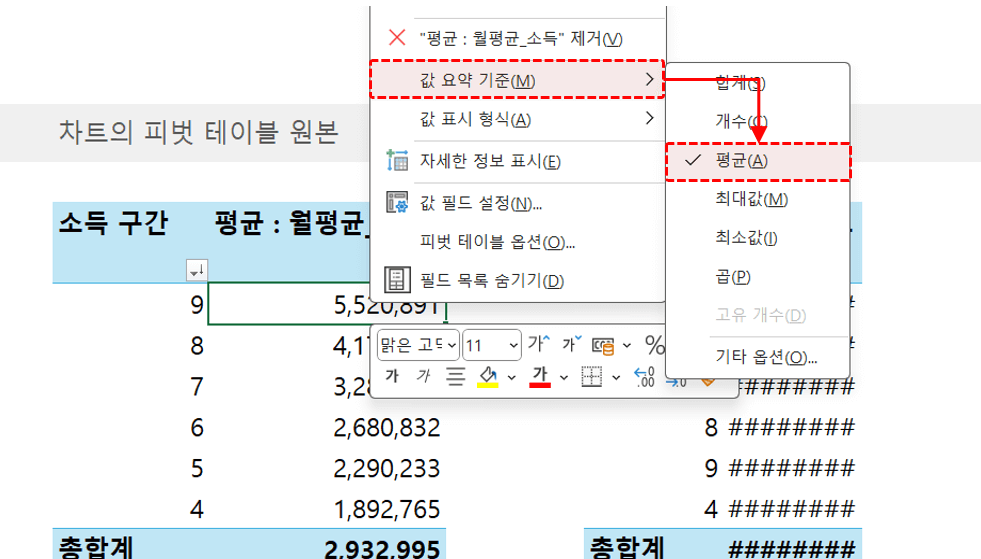
인사이트 분석 시트에서 피벗테이블의 집계 방식을 평균으로 변경합니다. - 집계 방식을 변경하면 서울시 상권별 소득/지출 데이터의 인사이트 분석이 완료됩니다.
· 소득이 가장 높은 상권은 9등급이지만, 식료품 지출은 5,6,7 등급 상권이 더 높은 것로 분석된다.
· 교육비는 월 평균 소득이 200-400만원인 구간인 상권에서 가장 높은 것으로 나타났다.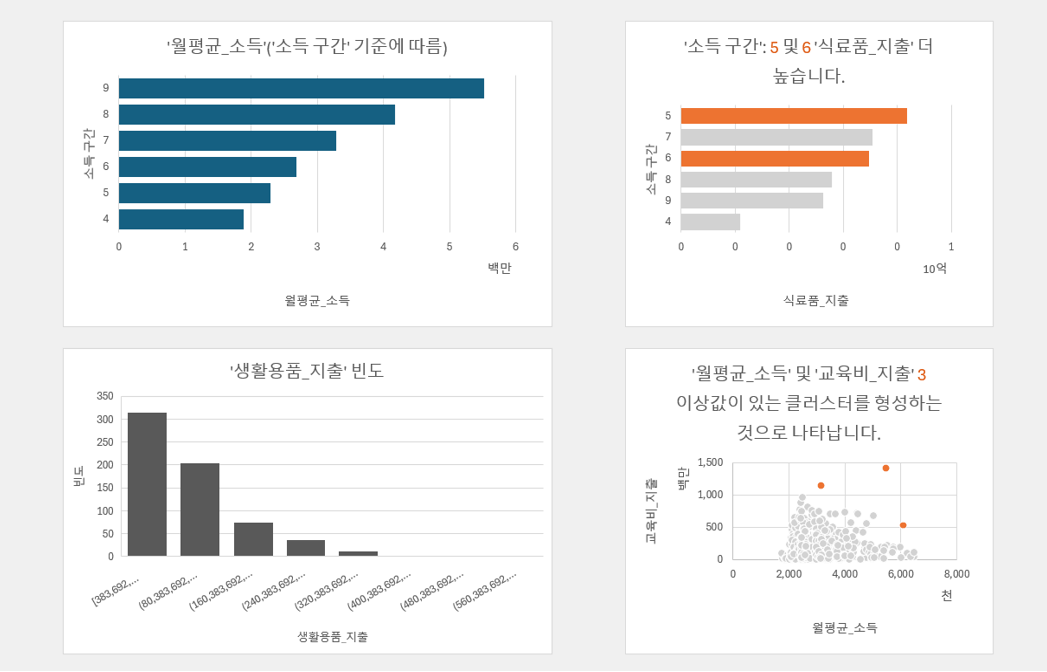
인사이트 분석이 완료됩니다.
코파일럿 파이썬 분석으로 상권 분석 보고서 만들기
이번에는 코파일럿의 파이썬 고급 데이터 분석을 사용해서 각 상권의 월 소득, 총 지출, 생활비 등의 항목을 5개 군집으로 분류하고 그 분포를 시각화하는 차트를 만들어보겠습니다.
- 예제파일에서 [파이썬 분석] 시트로 이동한 후, [홈] 탭 - [Copilot] 을 클릭해서 코파일럿을 실행합니다.
[홈] 탭 - 코파일럿을 실행합니다. - 기존 대화 내역이 있을 경우, 이를 초기화하고 진행하면 더욱 정확한 결과를 얻을 수 있습니다. 채팅 내역 상단에서 [채팅 기록]을 클릭하고 [새 채팅]을 클릭해서 대화 내역을 초기화합니다.
현재 작업과 무관한 이전 대화 내용이 있다면 대화내역을 초기화합니다. - 아래 프롬프트를 복사한 후, 구글 번역기에서 영어로 번역합니다. (2025년 4월 기준, 파이썬 고급 데이터 분석 요청은 영어로만 가능합니다.)
(한글) 파이썬을 사용해서 현재 데이터를 분석하려고 해. 현재 데이터의 Mth_Income, Net_exp, Grocery_exp, Clothing_exp, Transport_exp, Education_exp 필드를 5개의 군집으로 나누고, 각 필드별로 군집화 된 결과는 새로운 열을 추가해서 저장해.
특정 군집에 대해 longitute와 latitute별 군집의 분포를 나타낼 수 있도록 분산형 차트를 만들어서 출력해.
(영어) I'm trying to analyze the current data using Python.
Divide the Mth_Income, Net_exp, Grocery_exp, Clothing_exp, Transport_exp, and Education_exp fields of the current data into 5 clusters, and save the clustered results by each field by adding a new column.
Create a scatter chart to display the distribution of clusters by length and latitude for a specific cluster and output it. - 번역한 영문 프롬프트를 코파일럿 입력창에 붙여넣고 실행하면, 아래 그림과 같이 Python을 활용한 고급 데이터 분석 시작 안내와 함께 [고급 분석 시작] 버튼이 나타납니다. 이 버튼을 클릭해서 고급 분석을 시작합니다.
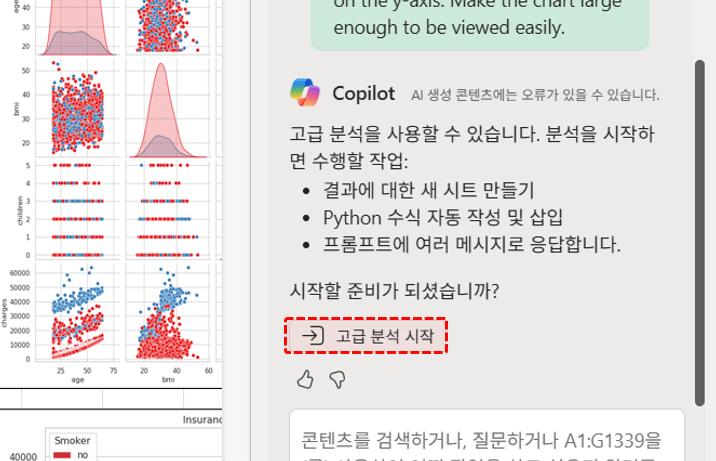
고급 분석 시작 버튼을 클릭해서 고급 분석을 시작합니다. - 버튼을 클릭하면 [분석] 시트가 추가되면서 파이썬을 활용한 고급 분석이 시작됩니다. 잠시만 기다리면 아래 그림과 같이 각 상권별 분포를 한 눈에 볼 수 있는 시각화 차트가 완성됩니다.
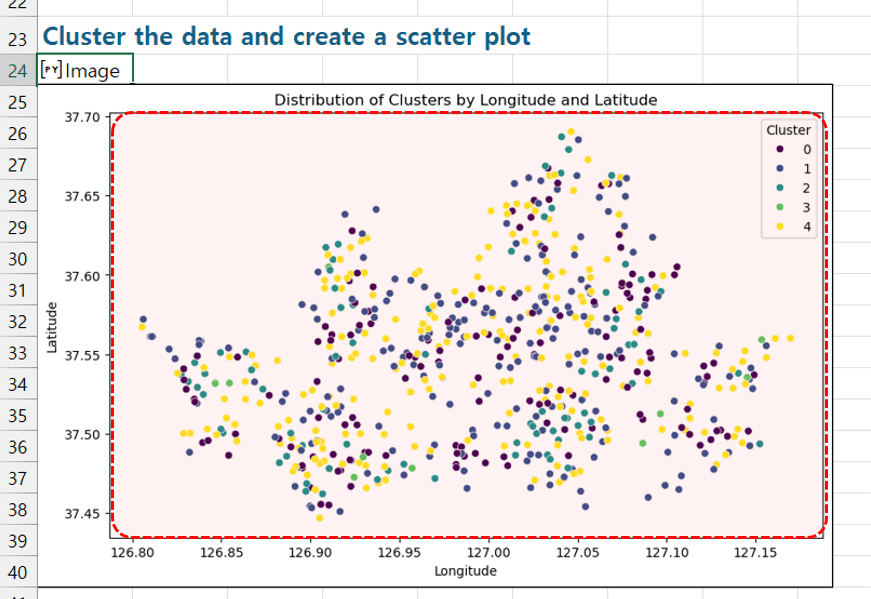
상권별 분포를 보는 시각화 차트가 완성됩니다. - 코파일럿을 사용하면 작성된 파이썬 코드도 편리하게 수정할 수 있습니다. 이번에는 A24셀에 파이썬 코드로 작성된 차트의 색상을 파란색 계열로 바꾸도록 요청해보겠습니다.
(한글) A24셀에 파이썬 코드로 작성된 차트를 파란색 계열로 바꿔
(영어) Change the chart written in Python code in cell A24 to blue color.
- 코파일럿에 요청하고 잠시만 기다리면 아래 그림과 같이 파란색 계열의 차트가 완성됩니다.
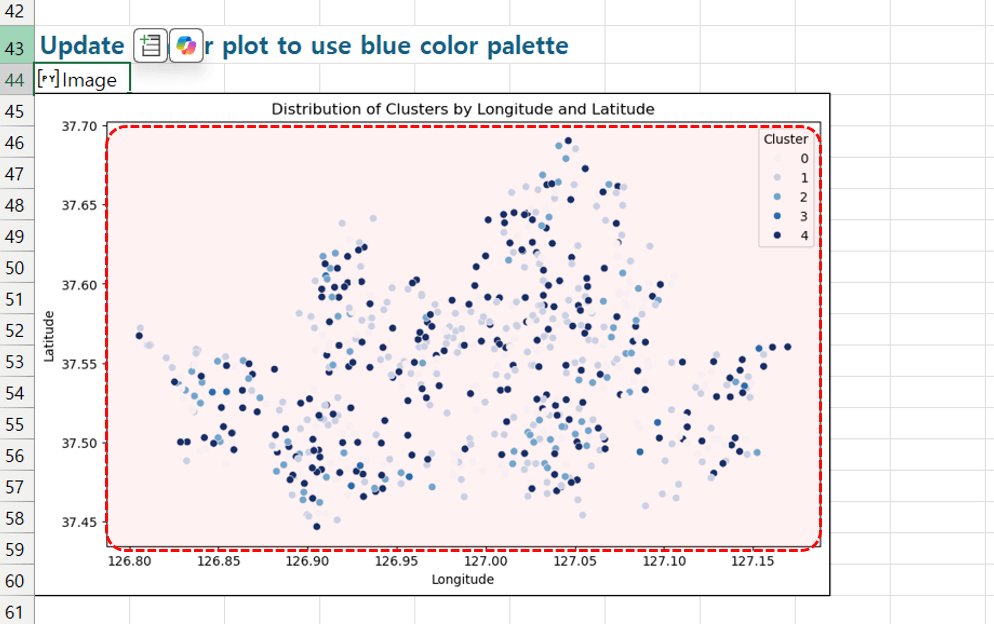
파란색 계열의 파이썬 분포 차트가 완성됩니다. - 동일한 과정으로, 지정한 셀의 데이터를 파이썬에 연동하도록 코드를 수정하면, 아래 그림과 같이 셀 안에 데이터를 바꿨을 때 실시간으로 업데이트되는 고급 분석 보고서를 만들 수 있습니다. 보고서를 만드는 과정은 영상 강의를 참고하세요!😊
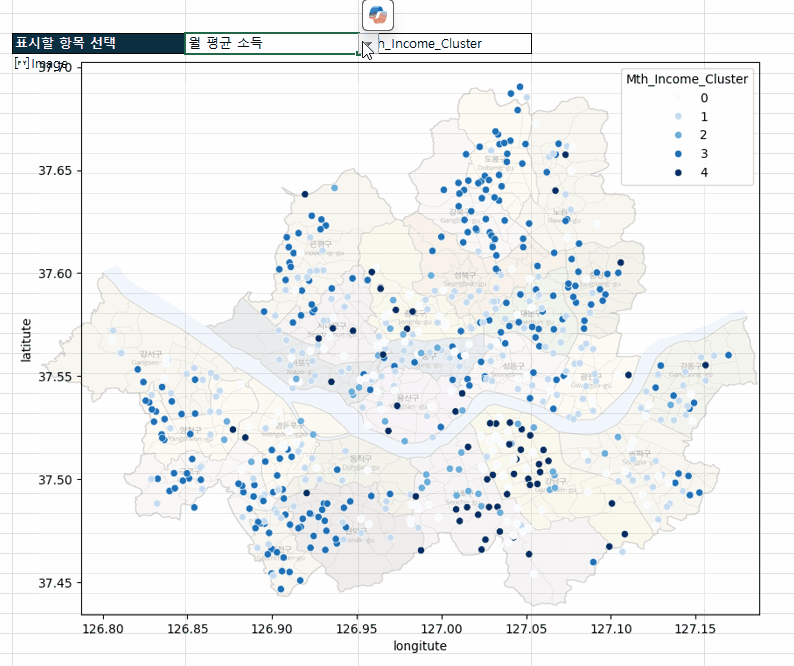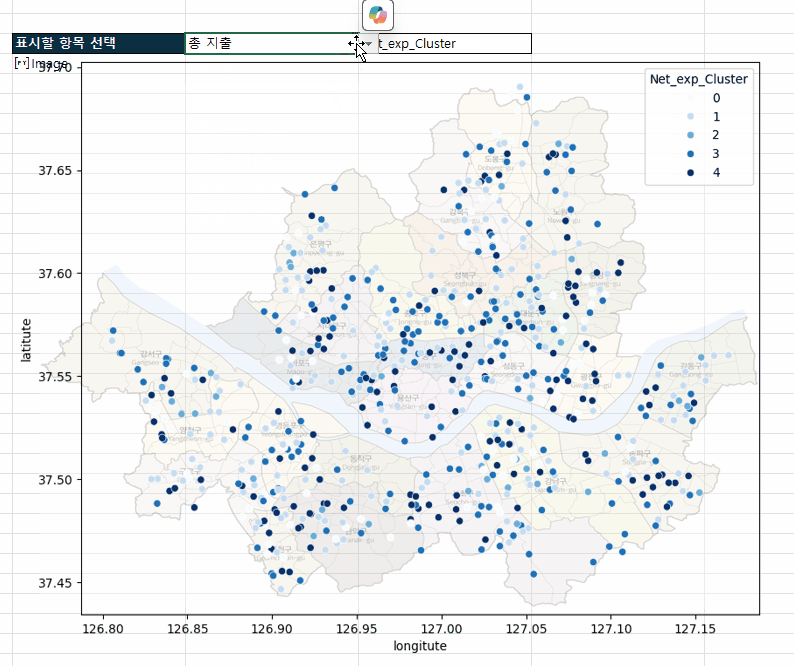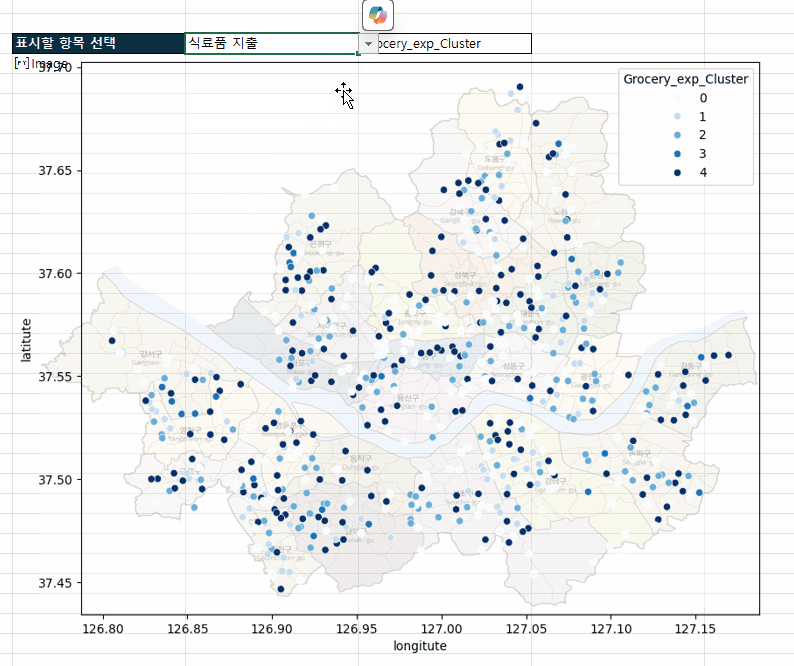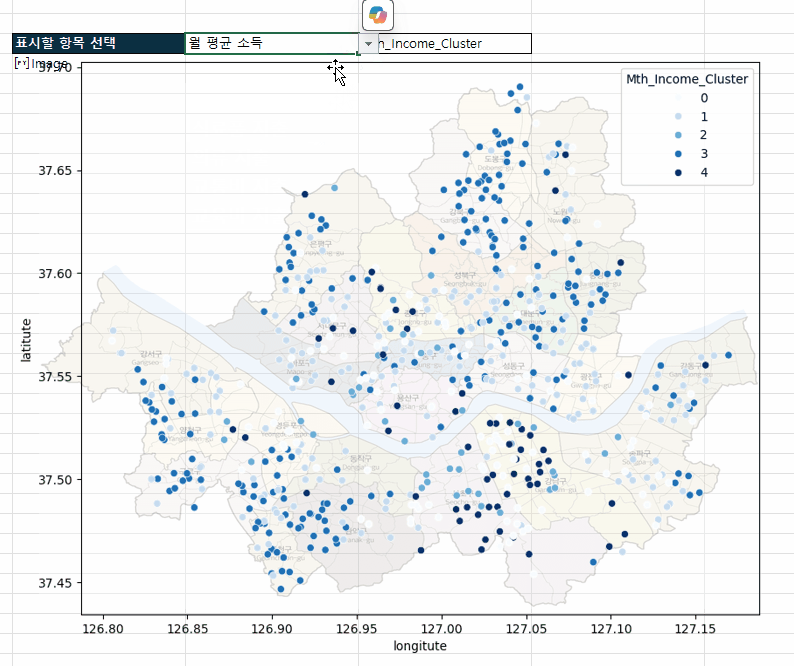
엑셀의 셀 값과 연동된 파이썬 분석 보고서를 만들 수 있습니다.
보험료 주요 항목 상관관계 분석 및 회귀 방정식 완성
마지막으로, 실무에서 바로 활용할 수 있는 중요한 분석 기법을 알아보겠습니다. 보험 가입자의 "나이, 성별, 체지방률(BMI), 자녀수, 흡연여부, 거주지역"에 따른 보험료율 데이터를 활용해서 신규 가입자의 보험료를 예측하는 모델을 구축하는 과정인데요!
이 과정을 현업에 적용하면 많은 부분에서 중요한 인사이트를 찾을 수 있습니다. 예를 들어, 특정 시간대에 특정 나이대 고객이 로그인을 하면 구매 확률이 높다는 패턴을 발견하고, 이를 바탕으로 마케팅 전략을 수립하는데 활용할 수 있습니다.
오빠두Tip : 만약 지금은 "질문에 대답하는 데 문제가 있습니다. 나중에 다시 시도하세요."라는 오류가 계속 표시된다면, 대화 내역을 초기화 후 다시 요청합니다. 새로 요청할 때에는, "현재 데이터를 파이썬을 사용해서 분석해"를 앞에 추가하는 것을 잊지 마세요!😊

- 예제파일에서 [보험료 예측] 시트로 이동한 후, 코파일럿을 실행하고 아래 프롬프트를 입력합니다. 만약 기존 대화 내역이 있을 경우, 대화 내역을 초기화하고 프롬프트를 실행하세요!
(한글) 파이썬을 사용해서 현재 데이터를 분석하자.
sex, smoker, region, bmi(체중 분포를 4그룹으로 분류) 변수에 대한 분포를 막대 차트로 시각화해.
4개의 그래프를 1x4 배열로 가로 한 줄에 배치해.
각 그래프에 다른 색상을 사용하고, x축은 변수명, y축은 count로 표시해.
차트는 큼지막하게 설정해서 보기 좋게 만들어.
(영어) Let's analyze the current data using Python.
Visualize the distribution of variables sex, smoker, region, and bmi (classify weight distribution into 4 groups) with a bar chart.
Arrange 4 graphs in a 1x4 array on one horizontal line.
Use different colors for each graph, and display the variable name on the x-axis and the count on the y-axis.
Make the chart large enough to be viewed easily. - [고급 분석 시작] 버튼을 클릭해서 파이썬 고급 분석을 실행합니다.
파이썬 고급 분석을 실행합니다. - 새 분석 시트가 추가되면서, "성별, 흡연여부, 거주지역, 비만도"의 분포를 확인할 수 있는 막대 차트가 출력됩니다.
· 남성 가입자가 여성 가입자보다 약간 많다.
· 비흡연자는 1000여명, 흡연자는 250여명으로 전체 가입자의 20% 정도가 흡연자이다.
· southeast 지역의 사용자가 약간 많다.
· 고도 비만(obese) 사용자가 월등히 높다.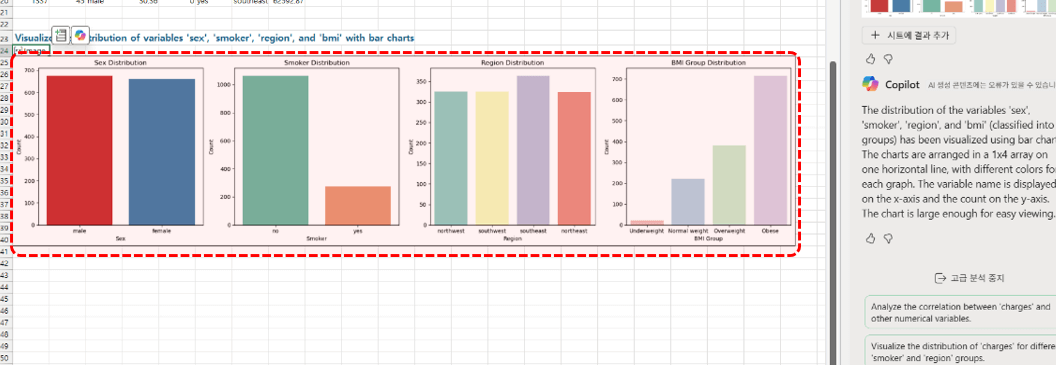
각 주요 항목의 분포를 확인하는 파이썬 차트가 출력됩니다. - 이번에는 각 항목별 "평균 보험료율"을 표시하는 차트로 수정해보겠습니다. 예제파일에서 A24셀에 파이썬 코드로 작성된 차트를 수정하도록 다음과 같이 요청합니다.
(한글) A24셀에 파이썬 코드로 작성된 차트의 y축을 평균 보험료 기준으로 변경해
(엉어) Change the y-axis of the chart written in Python code in cell A24 to the average insurance premium.
- 요청하면 아래 그림과 같이 각 항목별 평균 보험료 분석 결과가 표시됩니다.
· 남성 고객의 보험료가 여성 고객보다 조금 더 높다.
· 흡연 여부에 따라 보험료가 큰 차이가 난다.
· southeast 지역 거주자의 보험료가 조금 더 높다.
· 비만율이 높을 수록 보험료가 증가한다.
각 주요 항목의 평균 보험료 현황을 보여주는 차트가 완성됩니다. - 이번에는 각 변수별 상관관계를 분석하는 pairplot을 출력해보겠습니다. 아래 프롬프트를 코파일럿에 요청합니다.
(한글) 파이썬을 사용해서 현재 데이터를 분석하려고 해.
age, bmi, children, charge 관계를 보고, smoker 여부를 확인할 수 있도록 pairplot 차트를 생성해.
(영어) I'm trying to analyze the current data using Python. I'm going to create a pairplot chart to see the relationship between age, bmi, children, and charge, and to see if they are smokers or not.
- 잠시만 기다리면 아래 그림과 같이 pairplot이 출력되며, 다음과 같이 각 항목별 상관 관계를 해석할 수 있습니다.
· 나이가 많을 수록 보험료가 증가하는 추세를 보인다.
· bmi가 높을 수록 보험료가 증가하는 추세를 보인다.
· 흡연자의 경우 bmi가 높을 수록 보험료가 크게 증가하는 추세를 보인다.
· 비흡연자는 $8,000 - 10,000, 흡연자는 $24,000 및 $45,000 에 주로 분포한다.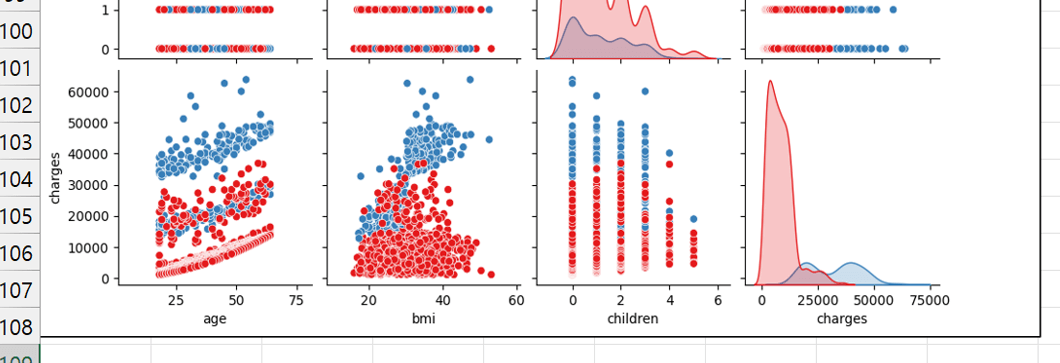
주요 변수의 상관관계를 보여주는 페어 플롯이 출력됩니다. - 이번에는 bmi와 흡연여부에 따라 보험료가 어떻게 증가하는지 분석해보겠습니다. 아래 프롬프트를 코파일럿에 요청합니다.
(한글) 현재 데이터에서 bmi에 따른 체중 분포를 'underweight, normal, overweight, obese' 4그룹으로 나눠. 그리고 각 그룹별 흡연여부에 따라 보험료를 볼 수 있는 막대 차트를 생성해.
(영어) In the current data, the weight distribution by BMI is divided into 4 groups: 'underweight, normal, overweight, obese'. Then, a bar chart is created that shows the insurance premium according to smoking status for each group.
- 잠시만 기다리면 아래 그림과 같이 비흡연자(빨간색)와 흡연자(파란색)의 비만도별 보험료율 차트가 출력됩니다.
· BMI가 높을 수록 보험료가 증가한다.
· 흡연자의 경우, 비만율이 높아지면 보험료가 크게 증가한다.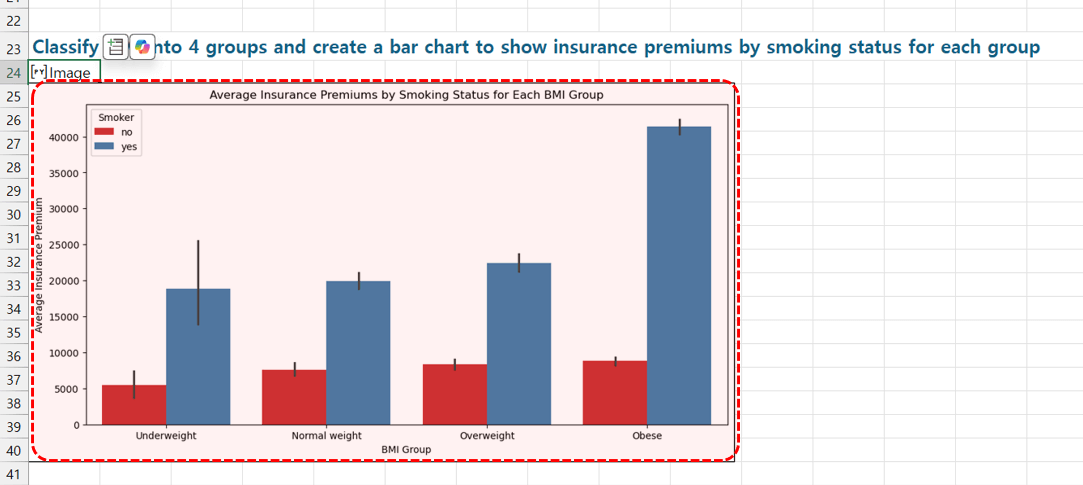
비흡연자와 흡연자의 비만도별 보험료 현황 차트가 출력됩니다. - 이전 단계에서 분석한 내용에 따라, 보험료에 크게 영향을 미치는 요소는 "나이, BMI, 흡연여부, BMI*흡연여부"로 확인했습니다. 이제 마지막으로 각 주요 변수에 따라 보험료를 예측하는 회귀 방정식을 만들어보겠습니다.
(한글) 각 변수 age, bmi, smoker 여부, bmi × smoker 를 기준으로 요금을 예측하는 선형 회귀 모델을 적용하고 회귀 방정식을 공식으로 출력해
(영어) Apply a linear regression model to predict the fee based on each variable age, BMI, smoker status, and BMI × smoker, and output the regression equation as a formula.
- 잠시만 기다리면 아래 그림과 같이 회귀 방정식이 완성됩니다.
charges = -2290.0080056391275 + 266.75824013111526*age + 7.109298446703368*bmi + -20093.508424093314*smoker + 1430.9204070520948*bmi_smoker

보험료 예측 회귀 방정식이 완성되었습니다. - 이제 완성된 방정식을 [보험료 예측] 시트에 붙여넣기 한 후, 방정식의 각 인수를 다음과 같이 적절히 수정해서 공식을 완성합니다.
=-2290.00800563912 + 266.758240131115*[@age] + 7.10929844670336*[@bmi] + -20093.5084240933*IF([@smoker]="yes",1,0) + 1430.92040705209*[@bmi]*IF([@smoker]="yes",1,0)

회귀 방정식을 붙여넣은 후, 각 인수를 적절히 수정합니다. - 마지막으로 실제 보험료와 예측한 보험료의 결정계수(R^2)를 구합니다. 비어있는 셀에 다음과 같이 RSQ 함수를 작성하면 약 83.6%의 정확도로 보험료를 예측하는 것을 확인할 수 있습니다.
=RSQ(범위1, 범위2)
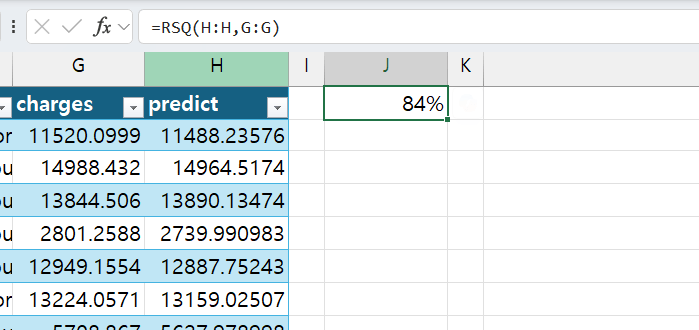
RSQ 함수로 회귀 방정식의 결정 계수를 도출합니다.
- 먼저 PC에서 코파일럿을 사용하려면 '자동 저장' 옵션을 켜야 합니다. 실습 파일을 실행한 후, 엑셀 화면 좌측 상단의 [자동 저장] 버튼을 클릭해서 원드라이브에 파일을 저장합니다. 저장한 파일은 원드라이브의 최상단 경로에 자동으로 저장됩니다.
M365 개인용(패밀리, 퍼스널) 라이선스는 코파일럿이 기본으로 제공됩니다.
단, 패밀리 라이선스의 경우 구독을 한 본인 계정에게만 코파일럿이 제공됩니다.
만약 M365 비즈니스를 사용하실 경우, 코파일럿을 별도로 구매해야 코파일럿이 표시됩니다.
한번 확인해보시겠어요? :) 감사합니다.